Проекции в Vertica: что это, как использовать, и почему не стоит создавать их под каждый запрос
Привет, меня зовут Иван Якунин, я продуктовый аналитик команды Fintech Marketplace. Мы занимаемся биллингом в Авито, изучаем как пользователи покупают на платформе, и с помощью этих данных создаём безопасные и быстрые платежные инструменты.
В Авито мы используем несколько аналитических баз данных, чтобы выстраивать свое DWH, и аналитику на его основе. Одна из них — Vertica. В статье я расскажу про проекции — одну из отличительных особенностей Vertica, которые мы используем, чтобы оптимизировать работу наших витрин и дашбордов. В условиях когда количество данных постоянно растет, а ресурсы кластера ограничены, проекции являются хорошим способом оптимизировать расчеты в базе данных.

Что такое Проекция
В большинстве баз данных таблица — это физическая структура, один объект, который хранится на диске. В Vertica таблица — это логическая структура, а физическим объектом, который хранится на диске, выступают как раз проекции. При этом одна таблица (логическая структура) может ссылаться на несколько проекций (физических структур).
Создавая таблицу, вы всегда создаёте вместе с ней её первую проекцию, которая в Vertica называется супер-проекцией. Следующие проекции, созданные уже вручную, будут копией данных супер-проекции, но при этом вы можете менять сортировку, сегментирование, фильтры, группировку данных.
Наиболее близкая аналогия из других БД — это материализованные представления (materialized view). Vertica обновляет проекции при изменении супер-проекции так же, как другие БД обновляли бы материализованные представления с флагом ON COMMIT (обновляется при изменении источников представления).
Таблица — логическая структура, и может ссылаться сразу на несколько проекций. Это позволяет SQL-запросам выполняться эффективнее: можно указывать одну таблицу, но оптимизатор Vertica будет анализировать при считывании какой проекции с диска запрос удастся выполнить дешевле и быстрее. Проще говоря, таблица — это символическая ссылка на несколько копий одних и тех же данных, собранных по-разному, и считывается та копия, которую будет дешевле всего использовать в запросе.
Теперь посмотрим на то, как выглядят проекции в коде. Создадим таблицу, с которой будем работать. Здесь я приведу небольшой семпл данных, который мы будем использовать.
create table public.test_projection (
id int,
event_date date,
amount int
);INSERT INTO public.test_projection select 1, '2024-03-09', 19584;
INSERT INTO public.test_projection select 2, '2024-03-10', 54686;
INSERT INTO public.test_projection select 3, '2024-03-11', 79387;
INSERT INTO public.test_projection select 4, '2024-03-12', 37693;
INSERT INTO public.test_projection select 5, '2024-03-13', 68438;
INSERT INTO public.test_projection select 6, '2024-03-14', 39868;Посмотрим, в какой момент у нас появляется проекция. Для этого посмотрим на план выполнения запроса, если мы запросим всю созданную нами таблицу:
Access Path:
+-STORAGE ACCESS for test_projection [Cost: 6, Rows: 6] (PATH ID: 1)
| Projection: public.test_projection_b0
| Materialize: test_projection.id, test_projection.event_date, test_projection.amount
| Execute on: All NodesВидим, что с диска на самом деле считывается проекция test_projection, но при этом у нее есть дополнительное название b0. Узнаем, откуда оно взялось.
SELECT GET_PROJECTIONS('public.test_projection');Вывод:
Current system K is 1.
# of Nodes: X.
Table public.test_projection has 2 projections.
Projection Name: [Segmented] [Seg Cols] [# of Buddies] [Buddy Projections] [Safe] [UptoDate] [Stats]
----------------------------------------------------------------------------------------------------
public.test_projection_b1 [Segmented: Yes] [Seg Cols: "public.test_projection.id",
"public.test_projection.event_date", "public.test_projection.amount"] [K: 1]
[public.test_projection_b0] [Safe: Yes] [UptoDate: Yes] [Stats: Yes]
public.test_projection_b0 [Segmented: Yes] [Seg Cols: "public.test_projection.id",
"public.test_projection.event_date", "public.test_projection.amount"] [K: 1]
[public.test_projection_b1] [Safe: Yes] [UptoDate: Yes] [Stats: Yes]Теперь понятно, что мы считали одну из реплик проекции. Их две, потому что коэффициент репликации K в кластере равен 1. Прежде, чем мы перейдем к проекциям, зафиксируем результат «до», чтобы было с чем сравнивать. Посмотрим на план запроса с группировкой по неделям.
EXPLAIN
SELECT
date_trunc('WEEK', order_created_at) as date_week,
sum(purchase_amount) as purchase_amount
FROM public.test_projection_iayakunin
GROUP BY 1Вывод:
Access Path:
+-GROUPBY HASH (GLOBAL RESEGMENT GROUPS) (LOCAL RESEGMENT GROUPS) [Cost: 5, Rows: 6] (PATH ID: 1)
| Aggregates: sum(test_projection.amount)
| Group By: date_trunc('WEEK', test_projection.event_date)
| Execute on: All Nodes
| +---> STORAGE ACCESS for test_projection [Cost: 4, Rows: 6] (PATH ID: 2)
| | Projection: public.test_projection_b0
| | Materialize: test_projection.event_date, test_projection.amount
| | Execute on: All NodesТеперь создадим новую проекцию для этой таблицы.
CREATE PROJECTION test_projection_week AS
SELECT
date_trunc('WEEK', event_date) as date_week,
sum(amount) as purchase_amount,
max(id) as purchase_id
FROM public.test_projection
GROUP BY 1;
SELECT start_refresh();Выбираем временной промежуток длиной в неделю, и группируем значения внутри таблицы. Вызов функции start_refresh необходим, чтобы запустить обновление проекции от супер-проекции. До момента её вызова значение UpToDate для этой проекции будет «no», и ей нельзя будет пользоваться. Кроме того, когда мы создали проекцию, то мы можем обращаться к ней напрямую по имени, минуя ссылку через основную таблицу.
Посмотрим, как изменился план выполнения предыдущего запроса.
Access Path:
+-GROUPBY PIPELINED [Cost: 2, Rows: 2 (NO STATISTICS)] (PATH ID: 1)
| Aggregates: sum(test_projection_week.purchase_amount)
| Group By: test_projection_week.date_week
| Execute on: All Nodes
| +---> STORAGE ACCESS for public.test_projection_week (Rewritten LAP) [Cost: 1, Rows: 2 (NO STATISTICS)] (PATH ID: 2)
| | Projection: public.test_projection_week
| | Materialize: test_projection_week.date_week, test_projection_week.purchase_amount
| | Execute on: All NodesТеперь в этом запросе считывается наша новая проекция, так как выполнение с ней дешевле — данные уже сгруппированы по неделям. Теперь базе данных нужно считать всего три строки. Разницу между десятью и двумя строками мы не почувствуем, этот пример тестовый, но на реальной витрине это позволит сэкономить много времени и ресурсов.
Что произойдет, если мы добавим данные в таблицу? Наша проекция сгруппирована по неделям, а супер-проекция нет. Попробуем добавить несколько дней, которые относятся к уже существующей неделе. Вот так выглядят значения до изменения данных, мы можем обратиться к проекции минуя таблицу-ссылку, напрямую по её имени:

Теперь вставим данные:
INSERT INTO public.test_projection select 7, '2024-03-15', 38657;
INSERT INTO public.test_projection select 8, '2024-03-16', 69382;
INSERT INTO public.test_projection select 9, '2024-03-17', 68482;После вставки данных мы можем не запускать обновление проекции, теперь Vertica будет самостоятельно поддерживать её в актуальном состоянии. Вот как выглядят данные после вставки новых дней:

Когда можно использовать проекции
Выше мы рассмотрели основную особенность проекций — они автоматически обновляют свою актуальность относительно супер-проекции и всё это скрывается за одной и той же таблицей. Это позволяет ускорять тяжёлые, повторяющиеся расчеты. Причём не только один и тот же повторяющийся кусок кода, но скорее код который использует похожие разрезы, так как Vertica принимает решение о том, какую проекцию считывать, анализируя стоимость запроса. Чаще всего подобные ситуации возникают, если в регламентных расчетах одну из витрин используют много зависящих от неё витрин, либо при визуализации данных на дашбордах. Дальше мы разберем второй случай, посмотрим как можно с помощью проекций ускорить построение графиков в дашборде.
Представим, что у нас есть таблица, в которой много сырых данных, и нам необходимо построить дашборд в большом количестве разрезов. Например, это могут быть события одного из продуктов, и нам необходимо настроить аналитику воронки этого продукта, и всех метрик, которые мы хотим видеть. Событий может быть очень много, и мы можем ждать загрузки дашборда довольно долго. Пользователи дашборда могут часто менять параметры графиков, это будет вызывать частые обращения к БД с однотипными запросами. С помощью проекций мы можем предсказать и рассчитать выполнение самых тяжелых и частых запросов, и ускорить выполнение дашборда.
Для примера будем использовать ту же таблицу, что мы создали раньше, но создадим для нее еще пару проекций, сгруппированных по месяцам и дням. И напишем очень простой запрос в redash, с помощью которого можно построить линейный график суммы покупок по датам с выбранной гранулярностью.
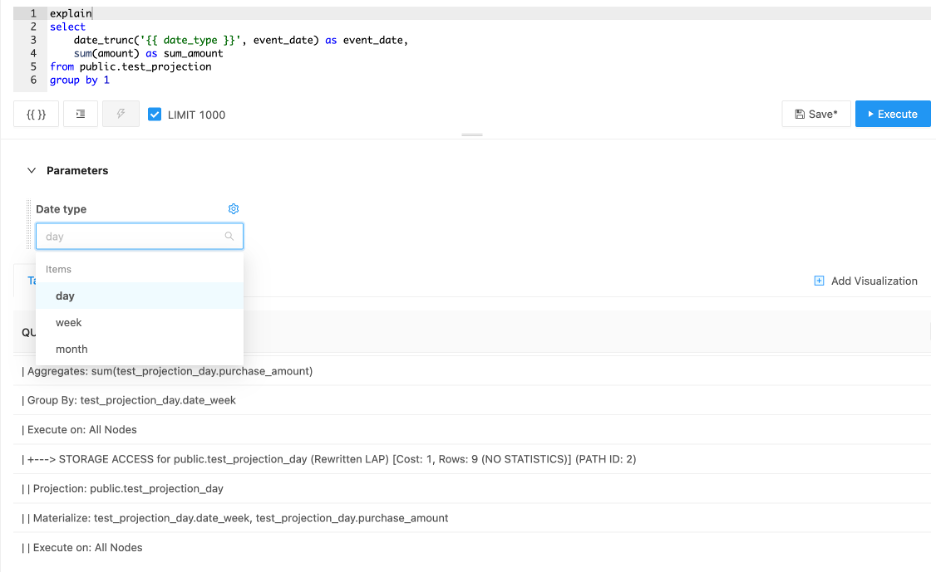
Так мы можем ускорить выполнение дашбордов которые строятся по большому количеству разрезов. При этом нам не придется беспокоиться о том, как обновлять каждый разрез, ставить его на расписание, и писать большие запросы.
Но важно помнить, что проекции занимают место в хранилище, поэтому не стоит создавать их под каждый запрос. Если мы создадим проекцию под запрос, который будет выполняться только один раз, то время расчёта проекции будет равно выполнению этого запроса. Важен баланс между ускорением расчетов, и ресурсами диска/процессора, которые мы тратим на расчёт и хранение проекции.
Итог
Проекции — это предварительно обработанные данные из основной супер-проекции таблицы.
То, что Vertica обновляет проекции самостоятельно открывает большое поле для оптимизации витрин и запросов в системах визуализации данных. Проекции можно использовать, когда у вас есть часто переиспользуемые куски кода, особенно если данных много. Ключевое слово «часто», потому что создавать проекции для одноразовых запросов плохо — они занимают место в хранилище и не помогают выиграть время расчёта.
