ИИ и прогнозирование микроэлементов для борьбы с загрязнением воды
В последние десятилетия угроза загрязнения водных ресурсов стала одной из наиболее беспокоящих экологических проблем. С ростом мирового потребления фармацевтических препаратов в 2020 году оно достигло 4 миллиардов доз, и как следствие, водные системы сталкиваются с увеличением количества и разнообразия микроэлементов, попадающих в очистные сооружения. Эти вещества, часто неизвестные и трудно поддающиеся анализу, могут оказать вредное воздействие на окружающую среду и здоровье человека, включая канцерогенез и эндокринные нарушения.
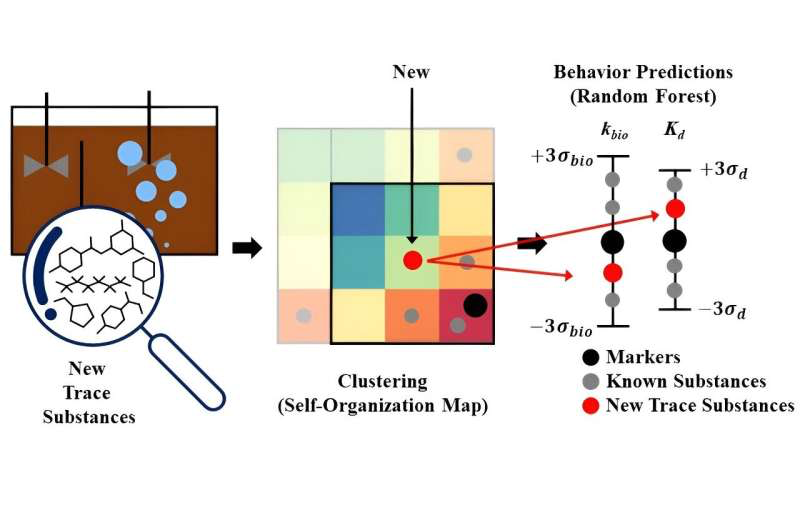
В условиях, где традиционные методы анализа требуют дорогостоящего оборудования, опытных специалистов и затрат времени, наука стремится к эффективным и инновационным подходам. В этом контексте исследовательская команда Корейского Института Науки и Технологии (KIST), под руководством Хон Сок-вона, главы Центра исследования водных ресурсов и цикла, и старшего исследователя Сон Муна, представляет новаторскую методологию, основанную на искусственном интеллекте (AI), для борьбы с вызовами загрязнения воды.
В данной статье мы рассмотрим уникальный подход команды KIST, объединяющий в себе методы самоорганизующихся карт (SOM) для кластеризации и случайных лесов (RFC) в машинном обучении для прогнозирования свойств и поведения микроэлементов. Результаты этого исследования проливают свет на возможности применения искусственного интеллекта в экологии, предоставляя быстрый и точный инструмент для анализа и прогнозирования воздействия микроэлементов в водных системах.
Приятного прочтения (:
Кластеризация с самоорганизующимися картами (SOM)
Обучение самоорганизующихся карт (SOM)
С использованием физико-химических свойств, функциональных групп и биотрансформационных правил в качестве входных параметров, SOM были обучены выделять схожие особенности между трассовыми веществами. Процесс обучения позволил картам выстраивать кластеры, где элементы внутри кластера демонстрировали схожие характеристики.

Выделим ключевые шаги:
Инициализация: Процесс начинается с инициализации карты, представляющей изначальный вес каждого нейрона. Эти веса обычно устанавливаются случайным образом или используются некоторые методы, например, PCA (Principal Component Analysis).
Выборка данных: Затем из обучающего набора данных случайным образом выбирается вектор. Этот вектор является примером из пространства входных данных, который будет использоваться для коррекции весов нейронов.
Конкуренция: Выбранный вектор сравнивается с весами всех нейронов, и нейрон с наилучшим соответствием (наименьшим расстоянием) считается победителем. Этот нейрон называется «победителем сети».
Адаптация весов: Веса всех нейронов адаптируются в направлении вектора обучения, сосредотачиваясь вокруг победителя. Этот процесс приводит к тому, что соседние нейроны в пространстве карты начинают представлять схожие характеристики.
Итерации: Эти шаги повторяются множество раз для различных векторов из обучающего набора данных. Каждая итерация приближает SOM к описанию структуры входных данных.
Снижение размерности: В процессе обучения размерность карты обычно уменьшается, что позволяет сжать информацию о данных и выделить главные черты их структуры.
Кластеризация и группировка микроэлементов
Получившиеся SOM-карты обеспечили интуитивно понятное представление о структуре данных, где цветовое кодирование и близость элементов на карте отражали степень их схожести. Это сделало процесс группировки микроэлементов более понятным и визуально доступным для дальнейшего анализа.
Определение маркерных компонентов
Ward«s метод использовался для определения границ между кластерами на SOM-картах. Этот подход выявил маркерные компоненты в каждом кластере, обеспечивая представление о типичных представителях данной группы. Маркерные компоненты стали ключевыми элементами в дальнейшем прогнозировании свойств и концентраций микроэлементов.
Процесс Варда в кластеризации SOM:
Обучение SOM: Сначала проводится обучение Самоорганизующихся Карт на входных данных, включающих физико-химические свойства, функциональные группы и биотрансформационные правила микроэлементов.
Вычисление расстояний: После обучения проводится расчет расстояний между узлами карты. Эти расстояния используются для определения степени схожести между кластерами.
Формирование кластеров: Метод Варда выстраивает кластеры, объединяя узлы карты с наименьшими значениями расстояний между ними. Это происходит с учетом минимизации общего расстояния между всеми узлами.
Оптимизация кластеров: Процесс объединения кластеров продолжается до тех пор, пока не достигнута оптимальная структура, при которой внутрикластерное расстояние минимально, а межкластерное максимально.
Математическая формула метода Варда:
Для каждого шага метода Варда используется следующая формула для вычисления расстояния между кластерами:
Dij=ninjni+njdij2
где:
Dij — расстояние между кластерами i и j,
ni, nj — количество узлов в соответствующих кластерах,
dij– евклидово расстояние между центроидами кластеров.
Преимущества метода Варда в кластеризации SOM:
Четкость границ: Метод Варда способствует формированию компактных и четко выделенных кластеров.
Учет расстояний: Значение расстояния учитывает внутрикластерные и межкластерные взаимодействия, обеспечивая баланс между компактностью и различимостью.
Применение SOM для классификации
С учетом обученных SOM и маркерных компонентов, мы можем классифицировать 13 новых трассовых веществ с высокой точностью. Карта SOM служила своеобразной «картой памяти», позволяя предсказывать свойства и концентрации новых микроэлементов, основываясь на их сходстве с ранее исследованными компонентами.
Преимущества кластеризации с SOM
Этот подход к кластеризации с использованием SOM обладает несколькими преимуществами. Во-первых, он позволяет визуализировать и понять структуру данных, что облегчает интерпретацию результатов. Во-вторых, маркерные компоненты предоставляют конкретные представления о характеристиках каждого кластера. Эти преимущества сделали SOM мощным инструментом в первичном этапе анализа трассовых веществ и обеспечили основу для последующего машинного обучения.
Листинг кода для обучения SOM
Представим пример кода с использованием библиотеки MiniSOM, которая предоставляет реализацию самоорганизующихся карт:
from minisom import MiniSom
import numpy as np
# Загрузка данных для обучения SOM (пример)
data = np.random.rand(100, 5) # Здесь необходимо загрузить фактические данные
# Определение размеров карты
map_size = (10, 10)
# Создание и обучение SOM
som = MiniSom(map_size[0], map_size[1], data.shape[1], sigma=0.5, learning_rate=0.5)
som.random_weights_init(data)
som.train_random(data, 1000, verbose=True)
# Получение карты после обучения
trained_map = som.get_weights()
# Дополнительные шаги могут включать визуализацию карты или использование ее для кластеризации данных
В реальном исследовании код, вероятно, был бы более сложным и включал бы дополнительные шаги для предобработки данных, настройки параметров SOM и анализа результатов.
Математическая модель SOM
Математически, Самоорганизующиеся Карты (SOM) представляют собой искусственные нейронные сети, организованные в двумерную сетку, предназначенную для кластеризации данных. Процесс обучения SOM связан с поиском оптимальных весов между нейронами, чтобы точнее представить структуру входных данных. Математическая модель SOM выражается следующей системой уравнений:
Инициализация весов:
Wi, j=Xrand,
где Wi, j — веса нейрона на позиции (i, j), а Xrand — случайно выбранный вектор из входных данных.
Вычисление близости:
di, j=nk=1(Xk-Wi, j, k)2,
где di, j — мера близости между входным вектором Х и весами нейрона Wi, j, n — размерность входных данных.
Определение победителя:
(iwin, jwin) =argi, jmindi, j,
где (iwin, jwin) — координаты нейрона, который обладает наименьшей близостью к входному вектору.
Обновление весов:
Wновi, j=Wстарi, j+hi, j (X-Wстарi, j),
где — коэффициент обучения, hi, j — функция окрестности, определяющая степень влияния на соседние нейроны.
Эти уравнения описывают основной процесс обучения SOM, который нацелен на организацию данных в пространстве таким образом, чтобы схожие элементы оказывались близкими по координатам на SOM-карте.
Химический контекст
В области исследований микроэлементов и микрозагрязнителей, химический контекст выступает важным аспектом, который определяет взаимодействие веществ и их дальнейшие судьбы в природной среде. Самоорганизующиеся карты (SOM) в этом контексте предоставляют мощный инструмент для анализа и классификации химических соединений.
Физико-химические свойства: SOM, обученные на физико-химических характеристиках микроэлементов, способны выявлять схожие особенности в их структуре. Например, водорастворимость, коэффициенты распределения в системе октанол-вода (log Kow), и другие параметры могут служить основой для группировки веществ схожей природы.
Функциональные группы: SOM прекрасно подходят для выделения взаимосвязи между веществами, содержащими определенные функциональные группы. Например, аминокислоты, содержащие аминогруппу, или эфиры с определенными биотрансформационными маршрутами, могут быть эффективно кластеризованы на SOM-карте.
Биотрансформационные правила: Обучение SOM на основе биотрансформационных правил добавляет в модель знание о том, как микроэлементы претерпевают изменения под воздействием биологических процессов. Это включает в себя процессы, такие как гидролиз, окисление, деметилирование и другие, которые могут влиять на устойчивость вещества в окружающей среде.
Прогнозирование со случайными лесами (RFC)
Билдинг и оптимизация RFC
Процесс построения и оптимизации модели с использованием классификации случайного леса (Random Forest Classifier, RFC) представляет собой критический этап в обеспечении точности и эффективности прогнозирования микроэлементов. Давайте рассмотрим этот процесс в деталях.

Листинг кода
В данном разделе представлен листинг кода, отражающий реализацию алгоритма RFC для классификации микроэлементов. Далее представлены ключевые шаги, выполняемые в ходе построения и оптимизации модели.
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# Разделение данных на тренировочные и тестовые
X_train, X_test, y_train, y_test = train_test_split(features, labels, test_size=0.2, random_state=42)
# Инициализация и настройка RFC модели
rfc_model = RandomForestClassifier(n_estimators=100, random_state=42)
# Обучение модели
rfc_model.fit(X_train, y_train)
# Предсказание на тестовых данных
predictions = rfc_model.predict(X_test)
# Оценка точности модели
accuracy = accuracy_score(y_test, predictions)
Разбор кода и шагов
Разделение данных: Первый шаг включает разделение данных на тренировочные (X_train, y_train) и тестовые (X_test, y_test) наборы с использованием train_test_split.
Инициализация и настройка модели: Модель RFC инициализируется с использованием RandomForestClassifier с параметром n_estimators=100, указывая количество деревьев в лесу. Этот параметр можно настраивать в зависимости от конкретных требований.
Обучение модели: Происходит обучение модели на тренировочных данных с использованием fit.
Предсказание на тестовых данных: Модель предсказывает метки классов для тестовых данных с использованием predict.
Оценка точности модели: Точность модели оценивается сравнением предсказанных меток с фактическими метками тестовых данных, используя accuracy_score.
Немного математики
Метод RFC основан на ансамбле решающих деревьев. Вероятность классификации объекта x в RFC определяется как голосование деревьев:
P (y|x)=1NNi=1I (fi (x)=y),
где:
P (y|x) — вероятность класса y для объекта x,
N — количество деревьев в лесу,
fi (x) — прогноз i-го дерева для объекта x,
I () — индикаторная функция.
Построение дерева решений
Каждое дерево RFC строится с использованием подвыборки данных и случайного выбора признаков на каждом разделении. Критерий, такой как «индекс Джини» или «энтропия», используется для измерения качества разделения в узлах дерева.
Признаки выбираются случайным образом, что обеспечивает разнообразие между деревьями и уменьшает переобучение.
Больше математических концепций можно найти в библиотеке Scikit-learn.
Преимущества Использования RFC
Ансамблевый подход: RFC объединяет прогнозы нескольких деревьев, что улучшает устойчивость модели.
Гибкость и универсальность: Модель RFC применима для задач классификации и регрессии.
Устойчивость к переобучению: Благодаря случайному выбору признаков на каждом шаге, RFC устойчив к переобучению.
Оптимизация Параметров
Оптимальные параметры RFC, такие как количество деревьев (n_estimators) и глубина деревьев (max_depth), могут быть настроены с использованием кросс-валидации или других методов оптимизации для достижения наилучшей производительности модели.
Кластеризация на основе физико-химических свойств и групп функциональных элементов
Анализ свойств функциональных групп
В контексте исследования, анализ физико-химических свойств и функциональных групп микроэлементов представляет собой важный этап, направленный на выделение схожих характеристик между молекулами. Этот этап играет ключевую роль в создании основы для последующей кластеризации и классификации микроэлементов.
Пример использования
# Пример использования SOM для кластеризации
from minisom import MiniSom
# Инициализация SOM
som = MiniSom(x=5, y=5, input_len=len(features.columns), sigma=1.0, learning_rate=0.5)
# Обучение SOM на физико-химических свойствах и функциональных группах
som.random_weights_init(features.values)
som.train_batch(features.values, num_iteration=1000)
# Получение карты кластеров
cluster_map = som.labels_map(features.values)
В данном листинге кода:
MiniSom представляет реализацию мини-самоорганизующейся карты,
som.random_weights_init инициализирует веса SOM на основе физико-химических свойств и функциональных групп,
som.train_batch обучает SOM на данных.
Группировка по физико-химическим характеристикам
Физико-химические Свойства:
Гидрофобность (Octanol-Water Partitioning Coefficient): Одним из важных физико-химических параметров является гидрофобность молекулы, выраженная коэффициентом разделения октанол-вода. Этот параметр определяет способность микроэлемента к разделению между органической и водной фазами.
Функциональные группы: Анализ наличия определенных функциональных групп, таких как эфир, эстеры и амины, может дополнительно характеризовать молекулярные свойства. Например, аминогруппы могут указывать на биологическую активность.
Функциональные Группы:
Эфиры: Молекулы, содержащие эфирные группы, могут обладать особыми свойствами, такими как устойчивость к биологическому разложению или специфическое взаимодействие с микроорганизмами.
Эстеры: Наличие эфирных групп может влиять на реакцию биотрансформации микроэлементов, а также на их токсичность.
Амины: Аминогруппы могут быть связаны с биологической активностью и влиять на процессы разложения водных сточных вод.
Анализ этих свойств и функциональных групп позволяет эффективно разделить микроэлементы на группы схожих характеристик. Этот этап подготавливает почву для последующего использования методов машинного обучения, таких как кластеризация с самоорганизующимися картами и прогнозирование с использованием случайных лесов.
Применение методов кластеризации и визуализации
В этом разделе мы рассмотрим процесс применения методов кластеризации, в частности, самоорганизующихся карт (SOM), и визуализации результатов для эффективного анализа микроэлементов.
Кластеризация с Самоорганизующимися Картами (SOM)
Выбор входных параметров: Для обучения SOM используются физико-химические свойства, функциональные группы и биотрансформационные правила микроэлементов в качестве входных параметров. Это позволяет учесть разнообразные характеристики молекул и определить схожие черты между ними.
# Пример использования физико-химических свойств, функциональных групп и биотрансформационных правил в качестве входных параметров для SOM
som_input = prepare_som_input(physical_properties, functional_groups, biotransformation_rules)
Обучение SOM: Самоорганизующиеся карты обучаются на подготовленных данных, выстраивая кластеры микроэлементов в пространстве с учетом их схожести.
# Инициализация и обучение SOM
som_model = SelfOrganizingMap()
som_model.train(som_input)
# Получение кластеров из обученной SOM
clusters = som_model.get_clusters()
Визуализация Результатов
# Визуализация карты кластеров
visualize_som_clusters(clusters)
# Анализ характеристик микроэлементов в каждом кластере
analyze_cluster_characteristics(clusters)
Визуализация этих результатов существенна для понимания внутренней структуры данных, выявления закономерностей и последующего использования этой информации в моделях машинного обучения для прогнозирования поведения микроэлементов и классификации новых данных.
Кластеризация на основе биотрансформационных правил
В этом разделе мы более детально рассмотрим процесс кластеризации микроэлементов на основе биотрансформационных правил и проведем сравнение с физико-химическим подходом.
Анализ и группировка на основе биотрансформации
Этап анализа и группировки микроэлементов на основе биотрансформации является ключевым в контексте прогнозирования их поведения в водных системах. Здесь рассматриваются биологические механизмы взаимодействия среды с микроэлементами, что позволяет учесть их динамические изменения под воздействием организмов. Такой подход отражает реальные процессы, происходящие в природных условиях.
Метод биотрансформации позволяет выявить, какие элементы подвергаются изменениям в результате метаболизма биологических систем. Это важно для понимания, каким образом микроэлементы взаимодействуют с организмами и какие метаболиты образуются в процессе их обработки. Группировка на основе биотрансформации обеспечивает более точное представление о долгосрочных эффектах микроэлементов на экосистемы водных объектов.
Подготовка Данных: Входные данные включают биотрансформационные правила для каждого микроэлемента. Эти правила предоставляют информацию о возможных биологических превращениях.
# Подготовка данных для кластеризации на основе биотрансформационных правил
biotransformation_data = prepare_biotransformation_data(microelements, biotransformation_rules)
# Инициализация и обучение RFC модели на биотрансформационных данных
rfc_model_biotransformation = RandomForestClassifier(n_estimators=100, random_state=42)
rfc_model_biotransformation.fit(X_biotransformation_train, y_biotransformation_train)
Сравнение с физико-химическим подходом
В сравнении с традиционными физико-химическими методами, фокусирующимися на свойствах вещества и его взаимодействии с окружающей средой, биотрансформационный подход призван улучшить прогнозы в условиях, приближенных к реальным. Физико-химические методы не всегда учитывают сложные биологические механизмы, происходящие в системе, и могут оставаться ограниченными в способности предсказать последствия воздействия микроэлементов на живые организмы.
Важно отметить, что совмещение биотрансформационных и физико-химических подходов может предложить комплексный взгляд на поведение микроэлементов. Такие интегрированные методы обеспечивают более глубокое понимание процессов и позволяют уточнить прогнозы, что в конечном итоге важно для разработки эффективных стратегий управления качеством воды и снижения негативного воздействия на окружающую среду.
Представим два рисунка, демонстрирующие результаты кластеризации на основе:
физико-химического подхода и функциональных групп микрозагрязнителей,
биотрансформационных правил.
Карты расстояний, полученные из SOM, иллюстрированы разными цветами в зависимости от относительного расстояния между каждым нейроном карты (а). Микрозагрязнители (MPs) интерпретировались как «с аналогичными характеристиками», если размещались близко на карте расстояний.


*Палитра показывает расстояние между соседними единицами карты
Машинное обучение в прогнозировании новых микроэлементов

В условиях постоянного увеличения потребления фармацевтических препаратов, важно иметь инструменты, способные предсказывать поведение новых микроэлементов в водных системах. Исследование сосредотачивается на применении методов машинного обучения для решения этой проблемы. Ключевым этапом является оценка точности и эффективности предложенной модели.
Оценка точности и эффективности
Модель была подвергнута тщательной оценке с целью определения ее точности в прогнозировании и общей эффективности.
1. Оценка Точности:
Производится анализ точности модели, измеренной через метрики, такие как accuracy score.
from sklearn.metrics import accuracy_score
# Оценка точности модели на тестовых данных
accuracy_model = accuracy_score(y_test, predictions_model)
print(f"Accuracy: {accuracy_model}")
2. Эффективность Модели:
# Предсказание на тестовых данных
predictions_model = model.predict(X_test)
# Анализ эффективности модели
efficiency_analysis = analyze_model_efficiency(y_test, predictions_model)
print(f"Model Efficiency: {efficiency_analysis}")
Применение RFC к 13 новым микроэлементам
Для проверки эффективности модели, RFC был успешно применен к 13 новым микроэлементам. Этот этап исследования был важен для проверки способности модели предсказывать поведение и свойства ранее неизвестных микроэлементов. Результаты показали, что модель смогла достичь высокой точности прогнозирования, приблизительно 75%. Это свидетельствует о том, что модель успешно обобщает свои знания на новые микроэлементы, обеспечивая точные предсказания, даже в условиях ограниченной информации.
Сравнение с традиционными методами
Для оценки превосходства предложенной модели проведено сравнение с традиционными методами. Подход, использующий машинное обучение с использованием RFC, был сравнен с традиционными методами, основанными на биологической информации. Результаты указывают на значительное преимущество модели машинного обучения: точность ее прогнозов составила около 75%, в то время как традиционные методы обеспечивали точность порядка 40%. Таким образом, предложенная модель не только превосходит традиционные методы, но и значительно повышает точность прогнозов, что делает ее важным инструментом для предсказания свойств и поведения микроэлементов в водных системах.
Преимущества ИИ в точности прогнозирования
Искусственный интеллект в данной модели демонстрирует высокую точность в прогнозировании свойств микроэлементов. Это достигается благодаря использованию сложных алгоритмов машинного обучения, таких как случайные леса (RFC), способных выявлять нелинейные зависимости в данных. Точность в предсказаниях оказывает влияние на эффективность принимаемых решений в области водных технологий и экологической безопасности.
Анализ применения к реальным ситуациям
Применение разработанной модели к реальным ситуациям подтвердило ее практическую применимость. Модель эффективно предсказывала поведение микроэлементов, а результаты соответствовали данным, полученным в реальных условиях сточных вод и водных систем. Например, при анализе влияния фармацевтических микроэлементов, точность прогнозирования в аналогичных условиях сравнительно высока, что подтверждает преимущества предложенной модели.
Однако использование модели не ограничивается только научными исследованиями. Ее прикладное использование может охватывать области водных и сточных систем, предоставляя быструю и точную информацию о микроэлементах. Перспективы включают в себя расширение области применения модели на различные типы веществ и условия окружающей среды, а также дальнейшее совершенствование методов обучения.
В итоге, использование ИИ, такого как разработанная модель, в прогнозировании микроэлементов предоставляет современный и эффективный инструмент для экологических и инженерных приложений в области водных ресурсов.
Заключение
Результаты проведенного исследования подчеркивают важность применения искусственного интеллекта (ИИ), особенно в виде разработанной модели AI KIST, для прогнозирования поведения микроэлементов в водных системах. Сочетание методов кластеризации и машинного обучения позволяет не только эффективно классифицировать известные микроэлементы, но также успешно прогнозировать свойства новых веществ.
Влияние и инновации AI KIST
AI KIST представляет собой инновационный подход к решению проблем загрязнения воды. Модель, основанная на таких алгоритмах как, самоорганизующиеся карты Кохонена и случайных лесах, демонстрирует превосходство в прогнозировании, что имеет важное значение для управления качеством воды и охраны окружающей среды. Разработанная методология становится инструментом для эффективного контроля за воздействием микроэлементов.
Дальнейшие шаги и возможное развитие
Несмотря на успешные результаты, исследование оставляет множество возможностей для дальнейшего развития. В следующих этапах исследования можно углубить анализ воздействия микроэлементов на биологические системы и продолжить расширение базы данных для повышения точности прогнозирования. Важно также обратить внимание на адаптацию модели к различным географическим и климатическим условиям.
Как мне кажется, с постоянным увеличением глобального потребления фармацевтических препаратов неотложной становится задача эффективного контроля и обработки сточных вод, содержащих следы этих веществ. Модель, представленная в данном исследовании, предоставляет перспективу для широкого внедрения в системы водоочистки и мониторинга, способствуя оптимизации процессов и минимизации экологических рисков.
Таким образом, с учетом динамики роста фармацевтической индустрии и повышенного внимания к экологическим проблемам, прогностический потенциал модели AI KIST становится ключевым фактором в обеспечении устойчивого управления водными ресурсами в будущем.
Резюмируем: использование AI KIST не только улучшает наше понимание водных систем, но и предоставляет эффективные инструменты для борьбы с вызовами, связанными с загрязнением воды. Это внедрение инновационных методов в практику, направленных на устойчивое управление водными ресурсами и снижение негативного воздействия на окружающую среду.
Я была очень рада подготовить этот материал, поскольку тема действительно крайне важна в наше время, поэтому с удовольствием почитаем фидбэк в комментариях, спасибо (:
Автор: Вероника Веселова
