[Перевод] Open AI Sora. Модели генерации видео как симуляторы мира
Мы исследуем крупномасштабное обучение генерирующих моделей на видеоданных. В частности, мы совместно обучаем модель распространения текста с учетом условий на видео и изображениях переменной длительности, разрешения и соотношения сторон.
Меня зовут Рушан, и я автор проекта Нейрон. Отмечу, что если среди читателей есть желающие помочь, и добавить дополнительный материал в статью, пожалуйста, свяжитесь со мной.
Мы используем архитектуру transformer, которая оперирует пространственно-временными фрагментами скрытых кодов видео и изображений. Наша самая крупная модель, Sara, способна генерировать видео высокой четкости продолжительностью в минуту. Наши результаты показывают, что масштабирование моделей генерации видео — многообещающий путь к созданию универсальных симуляторов физического мира.
Этот технический отчет посвящен нашему методу преобразования визуальных данных всех типов в унифицированное представление, которое позволяет проводить крупномасштабное обучение генерирующих моделей, и качественной оценке возможностей и ограничений Sora. Детали модели и реализации в этот отчет не включены.
Большая часть предшествующей работы была посвящена генеративному моделированию видеоданных с использованием различных методов, включая рекуррентные сети, генеративные состязательные сети, авторегрессионные трансформаторы, и диффузионные модели. Эти работы часто фокусируются на узкой категории визуальных данных, на более коротких видеороликах или на видеороликах фиксированного размера.
Sora — это универсальная модель визуальных данных — она может генерировать видео и изображения различной продолжительности, соотношения сторон и разрешения, вплоть до полной минуты видео высокой четкости.
Превращение визуальных данных в патчи
Мы черпаем вдохновение в больших языковых моделях, которые приобретают универсальные возможности благодаря обучению на данных интернет-масштаба. Успех парадигмы LLM частично обеспечен использованием токенов, которые элегантно объединяют различные способы работы с текстовым кодом, математикой и различными естественными языками.
В этой работе мы рассмотрим, как генеративные модели визуальных данных могут наследовать такие преимущества. В то время как у LM есть текстовые токены, у Sora есть визуальные исправления. Ранее было показано, что патчи являются эффективным представлением для моделей визуальных данных. Мы обнаружили, что патчи являются высокомасштабируемым и эффективным представлением для обучения генеративных моделей на различных типах видео и изображений.
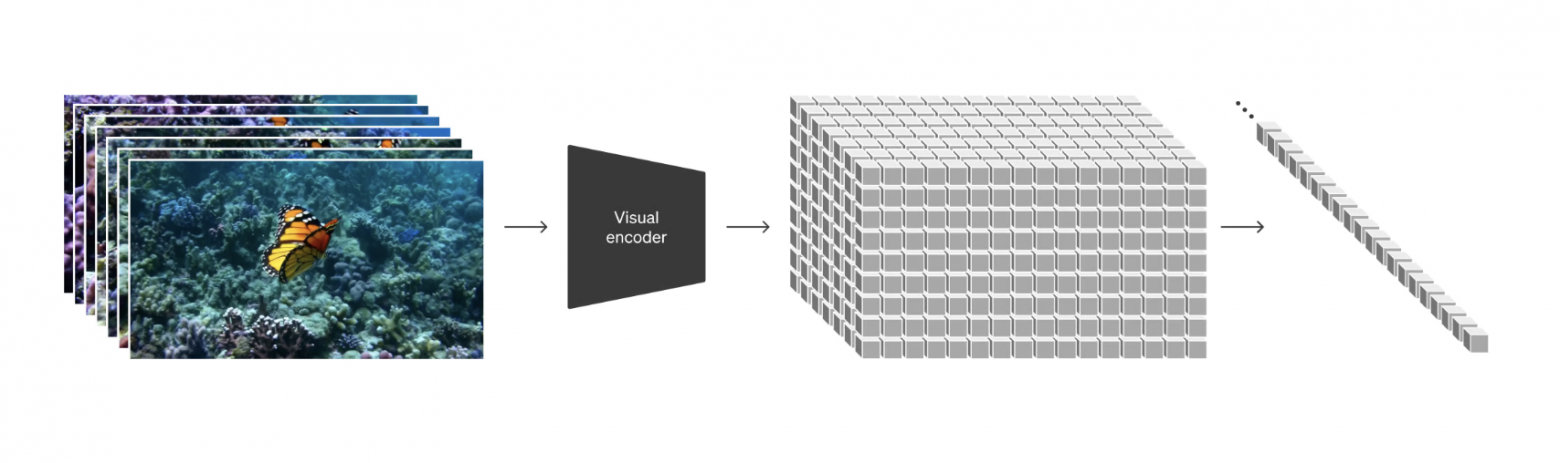
На высоком уровне мы превращаем видео в патче, сначала сжимая видео в скрытое пространство меньшей размерности, а затем разлагая представление на пространственно-временные патчи.
Сеть сжатия видео
Мы обучаем сеть, которая уменьшает размерность визуальных данных. Эта сеть принимает необработанное видео в качестве входных данных и выводит скрытое представление, которое сжимается как во времени, так и в пространстве. Sora обучается и впоследствии генерирует видео в этом сжатом скрытом пространстве. Мы также обучаем соответствующую модель декодера, которая отображает сгенерированные латенты обратно в пиксельное пространство.
Скрытые участки пространства-времени
Учитывая сжатое входное видео, мы извлекаем последовательность пространственно-временных фрагментов, которые действуют как токены-трансформаторы. Эта схема работает и для изображений, поскольку изображения — это просто видео с одним кадром. Наше представление на основе патчей позволяет Sora тренироваться на видео и изображениях с переменным разрешением, длительностью и соотношением сторон. Во время вывода мы можем контролировать размер сгенерированных видеороликов, размещая случайно инициализированные патчи в сетке соответствующего размера.
Масштабирующие трансформаторы для генерации видео
Sora — это диффузионная модель; учитывая входные зашумленные участки (и информацию об обработке, такую как текстовые подсказки), она обучена предсказывать исходные «чистые» участки. Важно отметить, что Sora является диффузионным трансформатором. Трансформаторы продемонстрировали замечательные свойства масштабирования в различных областях, включая языковое моделирование, компьютерное зрение, и генерацию изображений.

В этой работе мы обнаружили, что диффузионные трансформаторы эффективно масштабируются и в виде видео моделей. Ниже мы показываем сравнение видеосэмплов с фиксированными начальными значениями и входными данными по мере прохождения обучения. Качество выборки заметно улучшается по мере увеличения объема вычислений для обучения.
Переменная продолжительность, разрешение, соотношение сторон
Предыдущие подходы к генерации изображений и видео обычно изменяли размер, обрезали видео до стандартного размера — например, 4-секундные видеоролики с разрешением 256×256. Мы обнаружили, что вместо этого обучение на данных в их исходном размере дает несколько преимуществ.
Гибкость отбора проб
Сора Чан создает широкоэкранные видеоролики с разрешением 1920×1080p, вертикальные видеоролики с разрешением 1080×1920 и все, что между ними. Это позволяет Sora создавать контент для разных устройств непосредственно с их собственными соотношениями сторон. Это также позволяет нам быстро создавать прототипы контента меньшего размера перед созданием в полном разрешении — и все это с использованием одной и той же модели.
Улучшенное обрамление и композиция
Мы эмпирически обнаружили, что обучение на видео с их естественными соотношениями сторон улучшает композицию и кадрирование. Мы сравниваем Sora с версией нашей модели, которая делает все обучающие видео квадратными, что является обычной практикой для женщин, тренирующих генеративные модели. Модель, обученная квадратному кадрированию (слева), иногда генерирует видео, в которых объект виден только частично. Для сравнения, видео от Sara (справа) имеют улучшенное кадрирование.
Понимание языка
Для обучения системам преобразования текста в видео требуется большое количество видеороликов с соответствующими текстовыми субтитрами. Мы применяем к видео технику изменения субтитров, представленную в DELLE 330. Сначала мы разрабатываем модель с высокой степенью описательности, а затем используем ее для создания текстовых подписей ко всем видео в нашем обучающем наборе. Мы обнаружили, что обучение с высокой степенью описательности улучшает точность текста, а также общее качество видео.
Как и в DALLE 3, мы также используем GPT для преобразования коротких пользовательских подсказок в более длинные подробные параметры, которые отправляются видеомодели. Это позволяет Sora создавать высококачественные видеоролики, которые точно соответствуют пользовательским подсказкам.
Подсказки с изображениями и видео
Все результаты выше и на нашей целевой странице показывают примеры преобразования текста в видео. Но, конечно, также может быть предложено ввести другие данные, такие как уже существующие изображения или видео. Эта возможность позволяет Sora выполнять широкий спектр задач по редактированию изображений и видео — создавать идеально зацикленное видео, анимировать статичные изображения, продлевать видео вперед или назад во времени и т.д.
Анимация DALLE изображений
Sora способна генерировать видеоролики, используя изображение и подсказку в качестве входных данных. Ниже мы показываем примеры видеороликов, созданных на основе изображений DALLE 231 и DELLE 330.

A Shiba Inu dog wearing a beret and black turtleneck.

Monster Illustration in flat design style of a diverse family of monsters. The group includes a furry brown monster, a sleek black monster with antennas, a spotted green monster, and a tiny polka-dotted monster, all interacting in a playful environment.

An image of a realistic cloud that spells «SORA».

In an ornate, historical hall, a massive tidal wave peaks and begins to crash. Two surfers, seizing the moment, skillfully navigate the face of the wave.
Расширение сгенерированных видеороликов
Sora также способна расширять видео как вперед, так и назад во времени. Ниже приведены видео, которые были расширены назад во времени, начиная с сегмента сгенерированного видео. В результате каждое из четырех видео начинается не так, как другие, но все они приводят к одному и тому же финалу.
Мы можем использовать этот метод для расширения видеостены вперед и назад, чтобы создать бесшовный бесконечный цикл.
Редактирование видео из видео в видео
Диффузионные модели позволили использовать множество методов редактирования изображений и видео с помощью текстовых подсказок. Ниже мы применяем один из этих методов, SDEdit,32, к Sora. Этот метод позволяет Sora преобразовывать стили и окружение входных видеороликов с нулевого кадра.
Подключение видео
Мы также можем использовать Sora для постепенной интерполяции между двумя входными видео, создавая плавные переходы между видео с совершенно разными сюжетами и композициями сцен. В примерах ниже видео в центре интерполируются между соответствующими видео слева и справа.
Возможности генерации изображений
Sora также способна генерировать изображения. Мы делаем это, размещая участки гауссовского шума в пространственной сетке с временной протяженностью в один кадр. Модель может генерировать изображения различных размеров — с разрешением до 2048×2048.

Close-up portrait shot of a woman in autumn, extreme detail, shallow depth of field

Vibrant coral reef teeming with colorful fish and sea creatures

Digital art of a young tiger under an apple tree in a matte painting style with gorgeous details

A snowy mountain village with cozy cabins and a northern lights display, high detail and photorealistic dslr, 50mm f/1.2
Новые возможности моделирования
Мы обнаружили, что видео модели демонстрируют ряд интересных новых возможностей при масштабном обучении. Эти возможности позволяют Sora моделировать некоторые аспекты людей, животных и окружающей среды из физического мира. Эти свойства проявляются без каких—либо явных индуктивных искажений для 3D, объектов и т.д. — это чисто масштабные явления.
Согласованность в 3D. Sora может создавать видео с динамическим движением камеры. При перемещении и повороте камеры люди и элементы сцены последовательно перемещаются в трехмерном пространстве.
Долговременная согласованность и постоянство объекта. Существенной проблемой для систем генерации видео было поддержание временной согласованности при выборке длинных видеороликов. Мы обнаружили, что Sora часто, хотя и не всегда, способна эффективно моделировать как краткосрочные, так и долгосрочные зависимости. Например, наша модель может сохранять людей, животных и объекты, даже когда они закрыты или покидают кадр. Аналогичным образом, она может генерировать несколько снимков одного и того же персонажа в одном образце, сохраняя их внешний вид на протяжении всего видео.
Взаимодействие с миром. Газировка иногда может имитировать действия, которые влияют на состояние мира простыми способами. Например, художник может оставлять на холсте новые мазки, которые сохраняются с течением времени, или мужчина может съесть бургер и полюбить следы от укусов.
Имитация цифровых миров. Сора также способна имитировать искусственные процессы — одним из примеров являются видеоигры. Сора чан одновременно управляет игроком в Minecraft с помощью базовой политики, а также отображает мир и его динамику с высокой точностью. Эти возможности можно получить с нуля, запросив у Sora подписи с упоминанием «Minecraft».
Эти возможности позволяют предположить, что дальнейшее масштабирование видео моделей является многообещающим путем к разработке высокопроизводительных симуляторов физического и цифрового мира, а также объектов, животных и людей, которые в них живут.
Обсуждение
В настоящее время Sora имеет множество ограничений в качестве симулятора. Например, он неточно моделирует физику многих базовых взаимодействий, таких как разбивание стекла. Другие взаимодействия, такие как прием пищи, не всегда приводят к корректным изменениям состояния объекта. Мы перечисляем другие распространенные способы сбоя модели — такие как несогласованность, которая развивается в выборках с длительной продолжительностью или спонтанное появление объектов — на нашей целевой странице.
Мы считаем, что возможности, которыми обладает Sora сегодня, демонстрируют, что дальнейшее масштабирование видеомоделей является многообещающим путем к разработке эффективных симуляторов физического и цифрового мира, а также объектов, животных и людей, которые в них живут.
На этом наш пост подошел к концу. Поделитесь своим впечатлением в комментариях.
Больше информации о искусственном интеллекте, машинном обучении и роботах в моём аккаунте на Хабре и в проекте Нейрон, подписывайтесь, чтобы не пропустить будущих статей.
Всем знаний!
