Подводные грабли экспертных утилит при работе с инцидентами
Привет, Хабр!
Меня зовут Максим Суханов, я ведущий эксперт в команде CICADA8 Центра инноваций МТС Future Crew. Это подразделение отвечает, в том числе, за реагирование на инциденты кибербезпасности, форензику и реверс-инжиниринг вредоносного ПО. Ещё я занимаюсь другими интересными вещами, вроде немалварного реверса, например, файловых систем NTFS, FAT12/16/32, exFAT, реестра Windows и теневых копий.
Сегодня я расскажу о двух опасных типах ошибок DFIR-инструментов: когда использование утилиты приводит к отказу на целевом хосте и если инструмент выдаёт ошибочные, но ожидаемые результаты.
Этот пост — текстовая версия выступления на конференции SOC-Форум 2023. Вот тут можно посмотреть запись этого доклада

Во-первых, о ситуации, когда использование экспертной утилиты приводит к отказу на целевом хосте. А во-вторых, о случаях, когда инструмент выдаёт ожидаемые, но ошибочные результаты, из-за чего можно пропустить что-то важное.
Про какие утилиты пойдёт речь в статье:
агенты для мониторинга конечных точек: агенты EDR/XDR для серверов и рабочих станций
сборщики артефактов с конечных точек: утилиты, которые собирают артефакты по потенциальному инциденту
парсеры артефактов: утилиты, которые позволяют распарсить собранные артефакты (парсеры AmCache, например)
IoC-сканеры: утилиты, которые сканируют выбранный набор систем по индикаторам компрометации
а ещё библиотеки для всех этих утилит
Теперь перейдём к нескольким кейсам, на которых я покажу, что же может пойти не так при работе с DFIR-инструментами и почему.
Кейс libyara: отказ на целевом хосте
Вот, скажем, такая интересная ситуация: IoC-сканер приводит к отказу на стороне клиента, который доверяет нашим услугам.
В главной роли библиотека libyara. Она поддерживает язык YARA, предназначенный для поиска интересующих вас вещей по заданным правилам в файлах, памяти процессов, буферах и так далее. Эту библиотеку под капотом используют очень многие продукты в сфере кибербезопасности, поэтому на этот кейс стоит обратить особое внимание.
Итак, у нас есть несложная задача. Нужно просканировать память процессов Java на целевом хосте на наличие определённых строк. Целевая ОС — Linux. У нас есть простейшее YARA-правило на базе строк. В нём нет ничего, что можно было бы считать сложным — ни использования регулярных выражений, ни попыток детектировать машинный код, например.
Всё это запускается в скрипте, который получает список процессов через ps и фильтрует его через grep. Для выявленного процесса Java через xargs запускается yara, которой на вход передаются идентификатор процесса (PID) и файл с правилами. Простые исходные условия, совершенно ничего сверхъестественного.
Однако клиент возвращается с жалобой: при проверке определённых процессов (сервис Kafka) у клиента сканируемые процессы убиваются из-за ситуации out of memory. Как так вышло? Сейчас расскажу.
Как мы искали корень проблемы
Клиент лоялен и технически подкован, поэтому он попытался самостоятельно разобраться в происходящем, но у него не получилось. Дальнейшее сканирование памяти на хостах было приостановлено, поскольку мы не хотим, чтобы на основе наших рекомендаций клиент сломал себе бизнес-процессы.
Далее мы решили заняться отладкой. Для начала запросили у клиента вывод dmesg (команда, которая выводит буфер сообщений ядра ОС). В нём видно, что целевой процесс Java убивается системой из-за ситуации out of memory. То есть почему-то процесс хочет больше памяти, память закончилась, и приходит OOM Killer — ядро пытается спасти положение и убивает процесс, который потребляет слишком много памяти.

Вывод dmesg сообщает нам о возникновении ситуации Out of memory
Причина неясна, но это только пока. Разбираемся дальше.
С помощью утилиты strace пытаемся собрать список проблемных системных вызовов для процесса Java. Но среди них нет подозрительных с точки зрения потребления оперативной памяти.
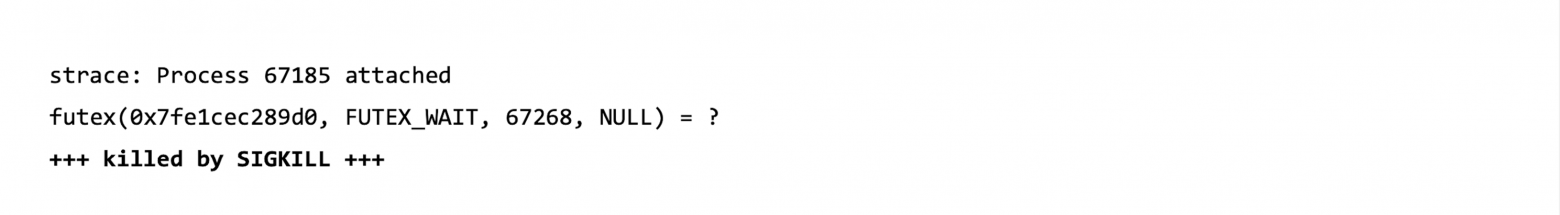
Вывод strace для Java — ничего подозрительного
Делаем аналогичный вывод strace для yara. Видим операции чтения памяти процесса, которые сначала возвращают какие-то байты (см. скриншот ниже), а потом происходит ошибка ввода-вывода. Очевидно, что ошибка возникает в тот момент, когда к процессу приходит OOM Killer. То есть тут ничего нового.
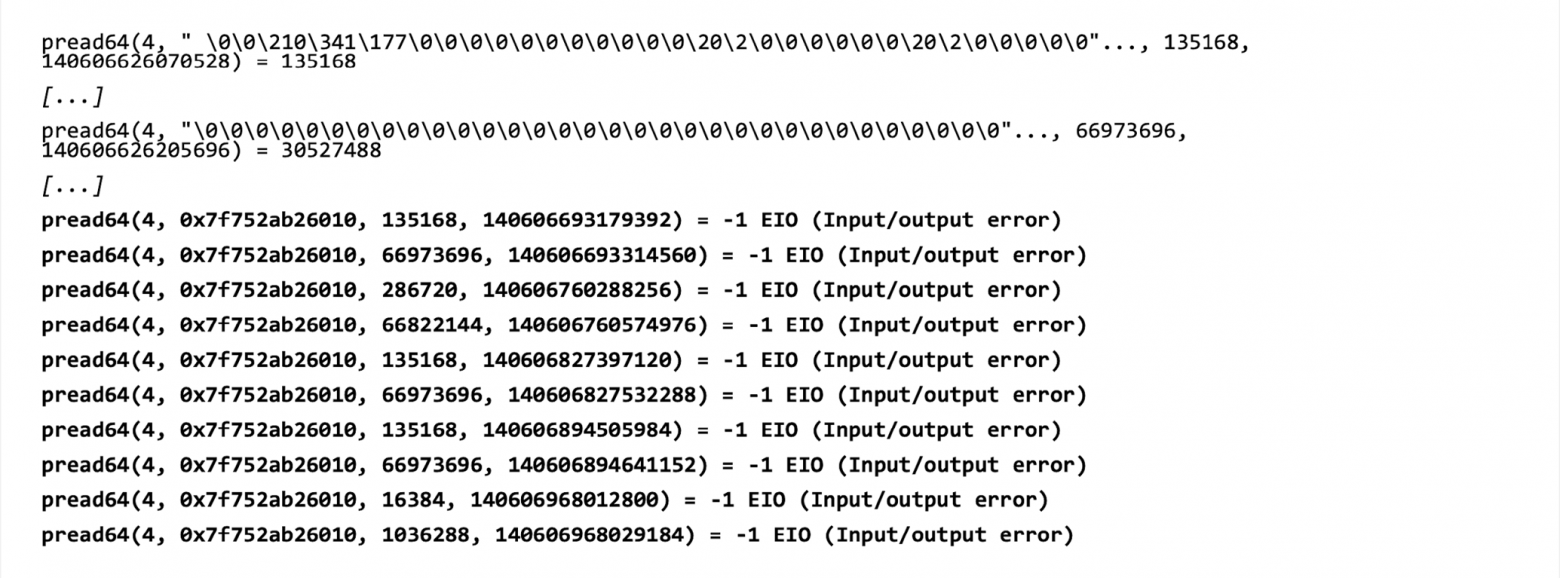
Вывод strace для yara — нет новой информации
Делаем карту памяти для процесса Java до того момента, когда его убивает ядро. Видим, что в этой карте очень много анонимных страниц — это страницы памяти, которым не поставлен в соответствие какой-либо файл на диске. В принципе, эта картина для Java ожидаема. Но мы всё ещё не знаем, почему же всё-таки происходит убийство процесса.

Карта памяти для Java — много анонимных страниц
Убийца — дворецкий?
В итоге поняли механизм возникновения ошибки. Вот как это работает:
целевой процесс Java потребляет много памяти (много для конкретного сервера, на котором он запущен)
значительная часть памяти этого целевого процесса находится в файле подкачки, чтобы высвободить оперативную память для других нужд
чтение утилитой yara памяти целевого процесса перемещает страницы из файла подкачки в оперативную память:
из-за этого целевой процесс (Java) потребляет всё больше и больше оперативной памяти во время его сканирования
в какой-то момент ядро больше не может это терпеть, и приходит OOM Killer. Занавес.
Нам удалось воспроизвести эту ситуацию в виртуальной машине. Также был создан тикет для разработчика libyara и предложен патч, но ошибка пока не исправлена. Поэтому будьте осторожны, если сканируете с помощью libyara что-то из памяти процессов в Linux (в Windows такая проблема не наблюдается).
Кейс Velociraptor: при сборе артефактов повреждаются копии файлов
Следующая ситуация связана с типичной логикой при сборе артефактов с работающей системы. Мы понимаем, что данные на диске постоянно меняются, поэтому если у нас в копии собранных из системы данных что-то повреждено, то это ожидаемо. А раз ожидаемо, то с этим можно просто смириться. Не на что тут смотреть, идём дальше.
Но не всегда это правильно.
Вот, например, Velociraptor — утилита для сбора телеметрии и артефактов с эндпоинтов. Может работать в режиме «быстро войти, собрать артефакты и выйти». Также её можно использовать в качестве EDR, если самостоятельно допиливать. Утилита поддерживает NTFS через библиотеку go-ntfs для чтения заблокированных файлов.
Всё хорошо, но есть проблема: при сборе артефактов регулярно повреждаются копии файлов, от $MFT до кустов реестра, и при парсинге возникает ошибка. С одной стороны, мы ожидаем, что такое может происходить, с другой — происходит это слишком часто.
Например, в копии куста реестра AmCache в архиве, собранном Velociraptor, нет части данных в середине. А те данные, что есть в середине, расположены по неправильным — «сдвинутым» — смещениям. Формат кустов реестра позволяет понимать, где какой блок данных должен находиться в файле. Поэтому вырезанный кусок явно бросается в глаза.
Воспроизведение ошибки и поиск причины
При этом другие утилиты (например, KAPE) к таким аномальным результатам не приводят: данные в гораздо большем числе случаев получаются целостными. Следовательно, проблема не в операционной системе.
То есть проблема есть, надо её признать и попытаться как-то отладить. Удалось под отладчиком успешно воспроизвести ошибку. Если копирование данных происходит медленно — например, когда в коде проставлены точки остановки, и на них делаешь длинные паузы, — то оказывается повреждено почти 100% файлов.
Причина? Я не знал, пока не создал тикет и разработчик не подтвердил мне одно из очень смелых предположений, причём не с первого раза. Сначала разработчик ответил что-то в обычном духе: «Это работающая система, данные могут меняться, ваш файл NTUSER.dat на диске во время копирования мог оказаться в других кластерах, поэтому смиритесь, такое бывает».
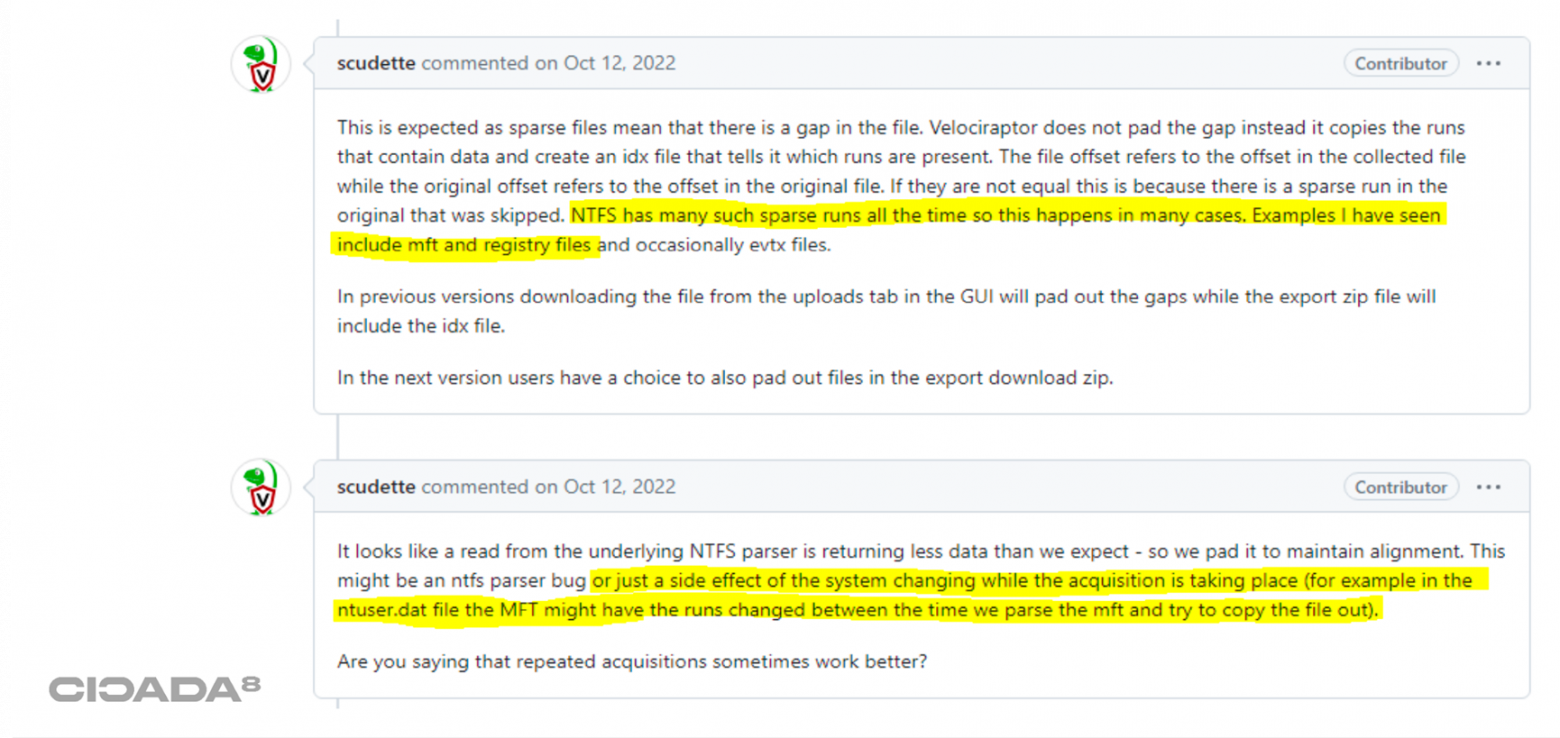
Ответ разработчика Velociraptor
Такое действительно может быть (см. «ожидаемо»), но у нас это происходит слишком часто. В итоге я предположил, что при копировании у нас что-то закрывает дескриптор, который открыт на диск C — для чтения с него напрямую. Попытка чтения из закрытого дескриптора приводит к тому, что данные возвращаются не полностью. Отсюда и возникает это «неполное чтение», которое в разных версиях утилиты Velociraptor приводит к несколько разным эффектам.
В целом, механизм возникновения ошибки следующий:
встроенная в утилиту Velociraptor библиотека ntfs-go поддерживает периодическое обновление дескриптора, используемого для чтения с диска
дескриптор закрывается и тут же открывается ещё раз — и так происходит каждые 60 секунд!
попытка чтения из закрытого дескриптора возвращает ошибку
это приводит к неполной записи в целевой файл:
— в старых версиях Velociraptor это приводит к «сдвигу» смещений в целевом файле
— в более новых версиях «сдвига» нет, но «зазоры» заполняются нулевыми байтами
При достаточно долгом (несколько минут) сборе данных неминуемо возникают повреждения. Это может быть, например, куст SOFTWARE как (чаще всего) самый большой куст реестра или что-то ещё, скажем, файл $MFT.
Кейс IoC-сканера Loki: не во все директории можно попасть рекурсивно
Есть такое поверье, что если мы просканируем диск C при помощи рекурсивных переходов, то мы доберёмся во все директории. Но это не так.
Например, есть утилита Loki — IoC-сканер с поддержкой YARA. Некоторые компании рекомендуют этот инструмент для сканирования инфраструктуры по известным YARA-правилам после инцидентов кибербезопасности. Однажды и у нас возникло желание порекомендовать клиенту эту утилиту. Но перед тем как советовать, я решил проверить, не случится ли чего-то неожиданного.
Далее типовой сценарий: сканируем файловую систему диска C — по YARA-правилам, всё просто. Однако есть важный нюанс: до апреля 2023 года утилита Loki поставлялась только в 32-битном варианте. А теперь внимание на экран:
что, с точки зрения 32-битной программы, хранится в директории «C:\Windows\System32\»?
правильно — содержимое «C:\Windows\SysWOW64\» (то есть директории с 32-битными ресурсами)!
, а оригинальное 64-битное содержимое хранится в директории «C:\Windows\Sysnative\»
, но этой директории нет в листинге «C:\Windows\», следовательно, рекурсивным обходом до неё невозможно добраться!
Но так мы вообще не сканируем реальное содержимое директории «C:\Windows\System32\». А там как раз может лежать что-то представляющее для нас интерес, например вредоносный драйвер.
Было создано сообщение об ошибке, и тут же был получен ответ от разработчика, мол, «используйте нашу другую утилиту THOR Lite». Но она не open source, так что не полностью нам подходит.
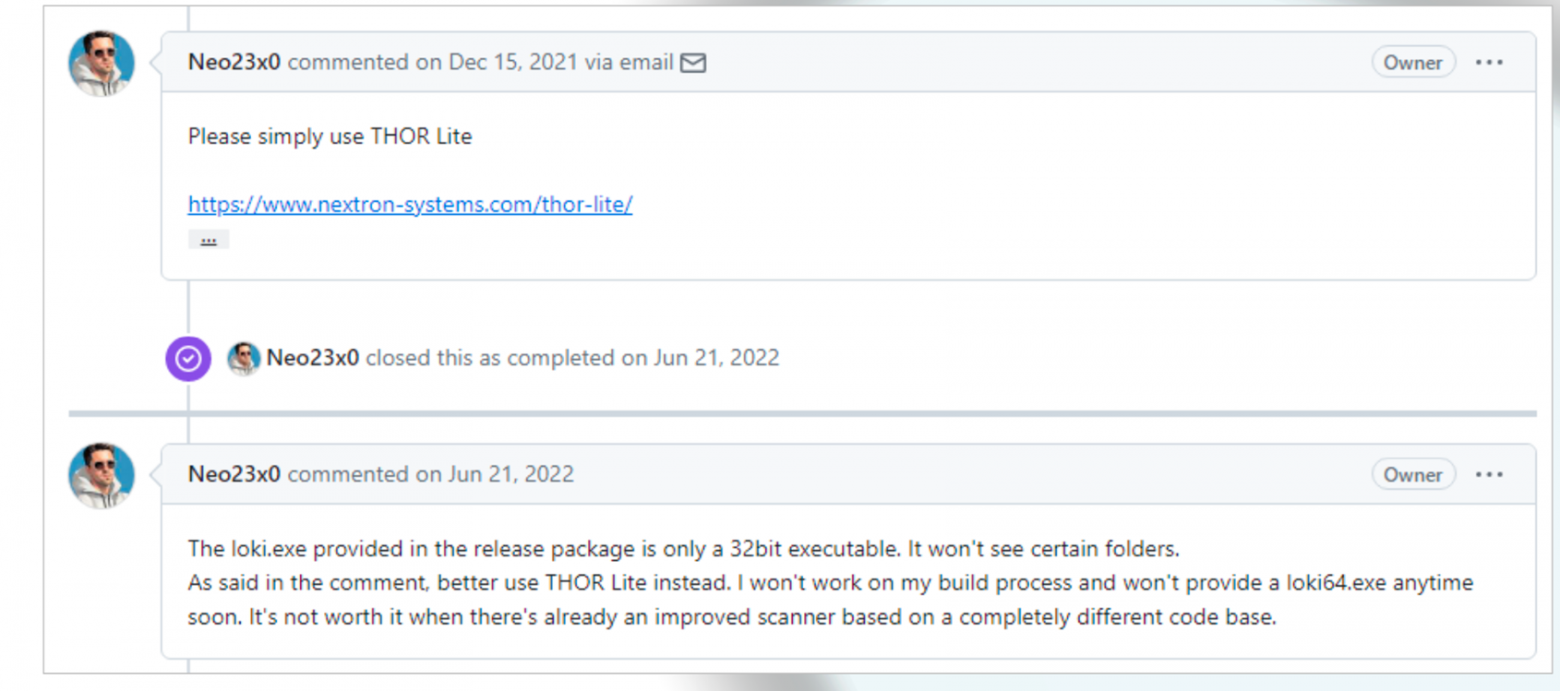
Ответ разработчика Loki: используйте другую утилиту, THOR Lite
Спустя полгода автор утилиты написал ещё одно сообщение, в котором сказал, что да, действительно, у 32-битной версии есть проблема с обходом директорий. Но он всё равно не будет делать билды для 64-битных систем.
Несмотря на это, позже он всё равно сделал 64-битный вариант Loki. Теперь, чтобы избежать проблемы, нужно просто использовать исполняемый файл под соответствующую архитектуру.
Кейс AmcacheParser: два способа хранения данных в кусте реестра AmCache
Четвёртый и последний кейс, который мы рассмотрим, связан с двойственным способом хранения данных в кусте реестра AmCache. Из-за этого некоторые утилиты (например, AmcacheParser) могут пропускать часть информации.
AmCache хранит некоторые данные телеметрии Windows. Например, в нём можно найти сведения об исполняемых файлах, присутствующих в системе, в том числе и ранее запущенных. Там есть SHA1-хеши от первых 31.457.280 байт каждого зафиксированного исполняемого файла и пути к ним. Лимит большой, так что в большинстве случаев можно считать, что это хеш от всего файла.
Этот артефакт активно используется защитниками в процессе расследования инцидентов. Все хеши прогоняют через VirusTotal и обнаруживают что-нибудь интересное — скажем, Mimikatz. Такое нередко встречается на практике.
Так вот, формат хранения данных внутри этого куста — то есть само дерево ключей и значений — различается в зависимости от версии Windows и версий библиотек Windows. Условно есть два формата, старый и новый, причём различия между ними весьма существенные. Например, в старом способе хеш хранится в значении с именем »101», а в новом — с именем «FileId», а также различается путь к искомому ключу:
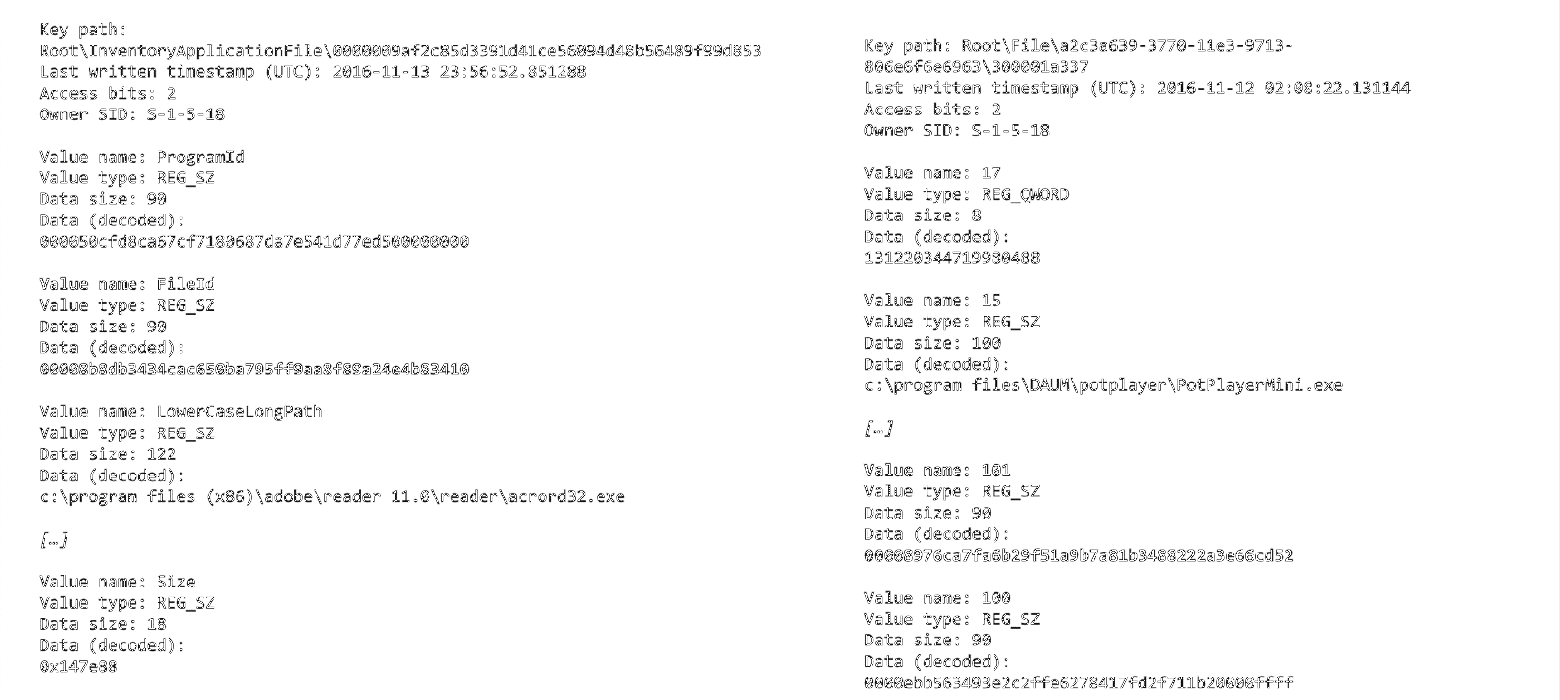
Два формата хранения дерева ключей и значений куста реестра AmCache: старый (справа) и новый (слева)
Поэтому утилита, которая извлекает артефакты из куста реестра AmCache, должна поддерживать оба формата. И тут мы подходим к AmcacheParser от Эрика Циммермана, поддерживающему оба способа хранения данных.
Но есть один нюанс: при начале парсинга файла утилита сама выбирает, какой там формат хранения, старый или новый, и далее использует какой-то один. Однако есть второй нюанс: в одном кусте реестра данные могут храниться двумя способами одновременно — переход со старого формата на новый происходит по мере обновления Windows.
И это приводит к тому, что при парсинге куста реестра AmCache могут извлечься не все данные о присутствующих или запущенных исполняемых файлах. В одном расследовании инцидента из-за такого поведения AmcacheParser мы не увидели в выводе утилиты Mimikatz. К счастью, это удалось вовремя выявить, так что это не привело к каким-то негативным последствиям.
Было создано сообщение об ошибке, разработчик его принял. Исправления пока нет, потому что предполагается, что этот случай — когда у нас одновременно применяются два способа хранения данных — граничный, а не повсеместный. Однако замечу, что в тестовых файлах реестра, которые были опубликованы NIST, данная ситуация также может быть обнаружена.
Обобщение
специалисты склонны чересчур доверять результатам работы утилит, если эти результаты соответствуют ожиданиям или если наблюдаемые аномалии могут быть объяснены чем-то ожидаемым
при этом ошибки в утилитах могут оставаться незамеченными годами
часть из этих ошибок может быть очевидна, если сравнить документацию разработчика и свою реализацию (если у инструмента открытый исходный код). Правда, проблема в том, что в современных условиях документация к программным интерфейсам ОС уже давно за гранью обозримого. То есть если мы ищем документацию к такому продукту, как Windows, нам нужен человек, который знает, где смотреть
может показаться, что последствия возникновения ошибок можно преодолеть за счёт повторной обработки тех же данных какой-нибудь другой утилитой, которая даст более корректный результат. Проблема тут в том, что на практике чаще всего этим никто не будет заниматься. Инцидент закрыт, отчёт написан, на то, чтобы искать, что там могло быть упущено, ни у кого банально нет времени
Из этого следует, что утилиты необходимо обязательно тестировать. Это не так уж просто, поскольку пока не знаешь о проблеме, сложно создать соответствующий тест-кейс. Ситуацию может спасти то, что одни и те же ошибки могут повторяться в разных местах и программах. То есть если мы обнаружили ошибку в одной утилите, то мы можем обнаружить её и в каких-то других инструментах. Высока вероятность повторения ошибки в независимо разработанных продуктах.
При этом можно брать баг-репорты для открытого ПО с GitHub и писать тест-кейсы для того софта, который вы разрабатываете или которым вы пользуетесь. Также полезно применять чек-листы: собрать список потенциальных проблем (от 20 пунктов и больше) и оценивать по ним программы, с которыми вы собираетесь работать.
Примеры тест-кейсов по итогам рассказанного выше:
если мы сканируем содержимое диска рекурсивными переходами, зайдёт ли этот сканер в директорию Sysnative? Это можно достаточно быстро оценить: создаём тест-кейс, прогоняем и получаем ответ в формате «да/нет»
если мы сканируем память другого процесса, защищаем ли мы его страницы от выхода из файла подкачки? Для этого создаём виртуальную машину, выделяем python-процессу огромное количество памяти, отправляем его в спячку и смотрим, что будет, если его просканировать тестируемой утилитой
если мы парсим AmCache, то поддерживает ли утилита оба способа хранения данных, применённых одновременно в одном и том же кусте реестра? Берём куст реестра и смотрим на результаты — соответствуют ли они нужному числу
рассмотренный кейс с Velociraptor — это действительно граничный случай. Кто же будет закрывать дескриптор на файл, из которого мы читаем? Тем не менее и такое бывает, так что это тоже можно тестировать
Таким образом можно создать более-менее исчерпывающий список известных проблем и использовать его для тестирования утилит.
