Как быстро и безболезненно выбрать лучшую из десяти выборок

Всем привет! Меня зовут Мария Ходякова, я продуктовый аналитик Тинькофф Страхования. В этой статье мы поговорим о множественном тестировании. Хорошо известен такой подход, как А/В-тестирование, когда в тесте участвуют две выборки. Но иногда нужно сравнить больше двух выборок и определить статистически значимо лучшую. Например, найти среди пяти баннеров в приложении лучший по конверсии продаж. Именно для этого и нужно множественное тестирование.
Статья имеет следующую структуру. Сначала описывается математическая постановка задачи и наиболее простой путь ее решения. Далее мы переходим к тому, как можно решить данную задачу более хитрым способом, существенно сократив размер данных, необходимых для тестирования.
В конце статьи также приводится библиотека с функциями для множественного тестирования по описанному алгоритму, реализованному на языке Python.
Длительность теста и постановка задачи
На идейном уровне множественное тестирование отличается от А/В только количеством выборок. Существенные различия скрываются на статистическом уровне. До начала теста нужно определить статистический критерий и минимальный размер выборки для получения стат. значимого результата. Минимальный размер считается по
уровню значимости и мощности — обычно
 и
и  соответственно;
соответственно; минимальному детектируемому эффекту MDE, или минимальному отклонению, которое хотим зафиксировать для метрики на выборках;
теоретической оценке дисперсии метрики, которая вычисляется по историческим данным;
отношению размеров выборок друг к другу.
При А/В-тесте этап определения критерия и выбора минимального размера не сильно чувствуется, поскольку создано много калькуляторов. Нам только нужно указать соответствующие параметры для нашего теста.
При множественном тестировании этап определения критерия и выбора минимального размера самый сложный. Если об этом совсем не подумать, может быть повышена вероятность ошибки. Если вникнуть, размер выборки может стать заоблачным, что отрицательно повлияет на длительность теста.
Разберемся с вычислением минимального размера выборки и возможными критериями для множественного тестирования как с идейной, так и с математической стороны.
Статистическая постановка задачи: определить лучшую из  выборок по целевой метрике (к примеру, конверсии). Здесь под лучшей выборкой понимается та, что дает наибольшее среднее значение целевой метрики. Сформулируем задачу статистически в случае выборок равного размера.
выборок по целевой метрике (к примеру, конверсии). Здесь под лучшей выборкой понимается та, что дает наибольшее среднее значение целевой метрики. Сформулируем задачу статистически в случае выборок равного размера.
Пусть  где
где  — множество возможных распределений. К примеру, в случае теста конверсий есть множество распределений Бернулли с различными параметрами
— множество возможных распределений. К примеру, в случае теста конверсий есть множество распределений Бернулли с различными параметрами![p \in [0, 1]](https://habrastorage.org/getpro/habr/upload_files/403/472/61d/40347261debc55c9244ecdb592c7aa07.svg) . Пусть
. Пусть  — математическое ожидание, или среднее значение,
— математическое ожидание, или среднее значение,  — дисперсия
— дисперсия  . Предположим, что случайные величины
. Предположим, что случайные величины  независимы в совокупности.
независимы в совокупности.
Тест, основанный на попарных сравнениях
Мы проверяем нулевую гипотезу  против гипотез вида
против гипотез вида
 утверждает невыполнение остальных гипотез.
утверждает невыполнение остальных гипотез.
Так, если на  -й выборке будет статистически наибольшее среднее значение целевой метрики, то мы примем гипотезу
-й выборке будет статистически наибольшее среднее значение целевой метрики, то мы примем гипотезу  . Иначе будет принята гипотеза
. Иначе будет принята гипотеза  . В примере с баннерами гипотеза
. В примере с баннерами гипотеза  означает, что
означает, что  -й баннер имеет наибольшую конверсию продажи,
-й баннер имеет наибольшую конверсию продажи,  — все баннеры дают одинаковую конверсию продажи.
— все баннеры дают одинаковую конверсию продажи.
Отметим, что при  получаем следующие классические гипотезы:
получаем следующие классические гипотезы:
предполагает равенство средних значений целевой метрики на обеих выборках,  и
и  — преобладание целевой метрики на первой и второй выборках соответственно.
— преобладание целевой метрики на первой и второй выборках соответственно.
Один из вариантов определения лучшей выборки — сравнение выборок попарно. То есть мы проводим  А/В-тестов. К примеру, при
А/В-тестов. К примеру, при  нужно провести
нужно провести  сравнений. Кажется, выглядит пугающе. Выясним, даст ли это желаемый результат.
сравнений. Кажется, выглядит пугающе. Выясним, даст ли это желаемый результат.
Размер одной выборки и построение критерия. Пусть заданы  — уровень значимости и вероятность ошибки второго рода соответственно,
— уровень значимости и вероятность ошибки второго рода соответственно,  для случая двух выборок с односторонней проверкой гипотезы по формуле:
для случая двух выборок с односторонней проверкой гипотезы по формуле:

где  —
—  -квантиль стандартного нормального распределения, уровень значимости
-квантиль стандартного нормального распределения, уровень значимости  вероятность ошибки второго рода
вероятность ошибки второго рода  минимальный детектируемый эффект
минимальный детектируемый эффект  . Тогда
. Тогда  — минимальный размер выборки для каждой из вариаций.
— минимальный размер выборки для каждой из вариаций.
Доказательство
Критерий где  будет сопоставлять верную гипотезу, то есть
будет сопоставлять верную гипотезу, то есть  .
.
Составим односторонние гипотезы  . Будем предполагать, что для проверки односторонних гипотез используется такая статистика
. Будем предполагать, что для проверки односторонних гипотез используется такая статистика  что в случае
что в случае  она принимает большие по модулю отрицательные значения.
она принимает большие по модулю отрицательные значения.
Положим
 — число, которое мы выберем по уровню значимости
— число, которое мы выберем по уровню значимости  позднее,
позднее,  —
—  -квантиль предельного распределения статистики
-квантиль предельного распределения статистики  при гипотезе
при гипотезе  . Если мы проверяем
. Если мы проверяем  против
против  вероятность ошибки первого рода такого критерия будет равна
вероятность ошибки первого рода такого критерия будет равна  причем в случае ненулевой гипотезы мы можем утверждать стат. значимо об отличии
причем в случае ненулевой гипотезы мы можем утверждать стат. значимо об отличии  от
от  в одну или другую сторону.
в одну или другую сторону.Логично положить  если
если
 не пересекаются. Если ни для какого
не пересекаются. Если ни для какого  условие не выполнено, полагаем
условие не выполнено, полагаем  .
.Можно посчитать вероятность ошибки первого рода критерия
 , и вероятность ошибки второго рода, равную
, и вероятность ошибки второго рода, равную  . Пусть размер выборки в каждой группе, был выбран так, чтобы вероятность ошибки второго рода при проверке
. Пусть размер выборки в каждой группе, был выбран так, чтобы вероятность ошибки второго рода при проверке  против
против  была равна
была равна  . Вообще говоря, может зависеть от
. Вообще говоря, может зависеть от  и
и  поэтому мы выберем максимальный из всех комбинаций. Рассмотрим
поэтому мы выберем максимальный из всех комбинаций. Рассмотрим  . Тогда
. Тогда так, чтобы при проверке
так, чтобы при проверке  против
против  вероятность ошибок первого и второго рода не превосходила соответственно
вероятность ошибок первого и второго рода не превосходила соответственно  и
и  мы сможем стат. значимо обнаружить отклонение максимума порядка
мы сможем стат. значимо обнаружить отклонение максимума порядка  с вероятностью ошибок первого и второго рода, не превосходящей
с вероятностью ошибок первого и второго рода, не превосходящей  и
и  соответственно.
соответственно.Что и требовалось доказать.
При множественном тестировании  выборок с уровнем значимости
выборок с уровнем значимости  и вероятностью ошибки второго рода
и вероятностью ошибки второго рода  сравнивая попарно выборки, мы проводим
сравнивая попарно выборки, мы проводим  А/В-тестов с уровнем значимости
А/В-тестов с уровнем значимости  и вероятностью ошибки второго рода
и вероятностью ошибки второго рода  . Если некоторая
. Если некоторая  -я выборка стат. значимо лучше каждой другой выборки, принимается гипотеза
-я выборка стат. значимо лучше каждой другой выборки, принимается гипотеза  где
где  иначе принимается гипотеза
иначе принимается гипотеза  . Математически критерий теста описан в доказательстве.
. Математически критерий теста описан в доказательстве.
Выбранное решение не самое простое. Без каких-либо доказательств мы могли прийти к тому, что можно провести  попарных сравнений с уровнем значимости
попарных сравнений с уровнем значимости  и вероятностью ошибки второго рода
и вероятностью ошибки второго рода  .
.
Моделирование. Мы провели математический разбор критерия, основанного на попарных сравнениях, который будем называть простым решением. Но что это даст на практике? Чтобы с этим разобраться, обратимся к моделированию.
Мы не хотим ошибаться слишком часто, следовательно, мы будем контролировать вероятность ошибки первого рода, то есть вероятность отклонить нулевую гипотезу при ее справедливости. Величина эта теоретическая, поэтому мы промоделируем частоту неверного отклонения нулевой гипотезы, близкую к истинной вероятности ошибки первого рода при достаточном количестве моделирований. Для примера используем распределение Бернулли, как в случае с тестом конверсии.
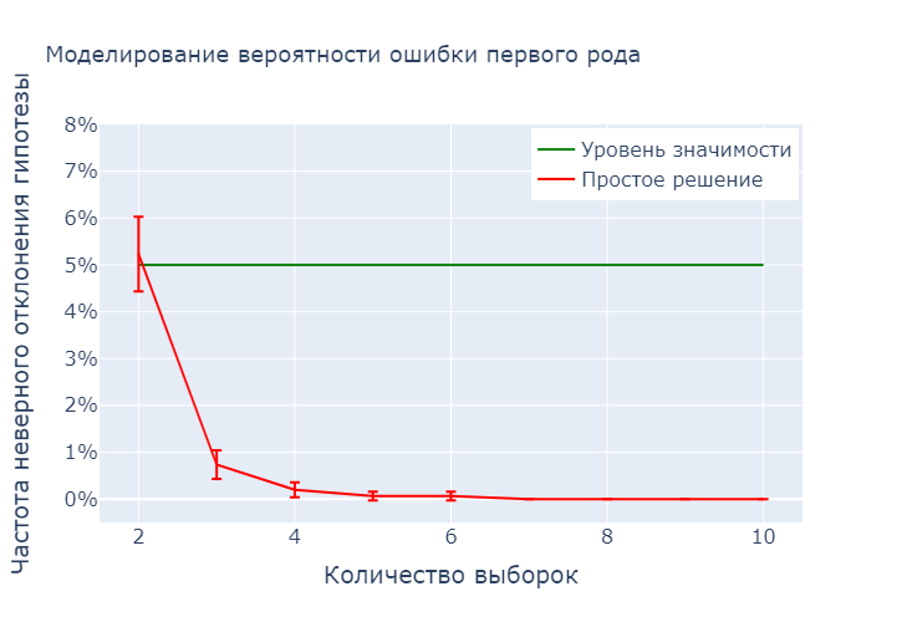
При увеличении количества выборок частота неверного отклонения нулевой гипотезы быстро убывает к нулю. Для нас это плохо, поскольку у нас нет цели быть слишком осторожными. Мы заложили уровень значимости 5% и хотим оставаться на этом уровне.
Возникает вопрос: на что влияет наша чрезмерная осторожность? Посмотрим на минимальный размер одной выборки в зависимости от количества выборок.
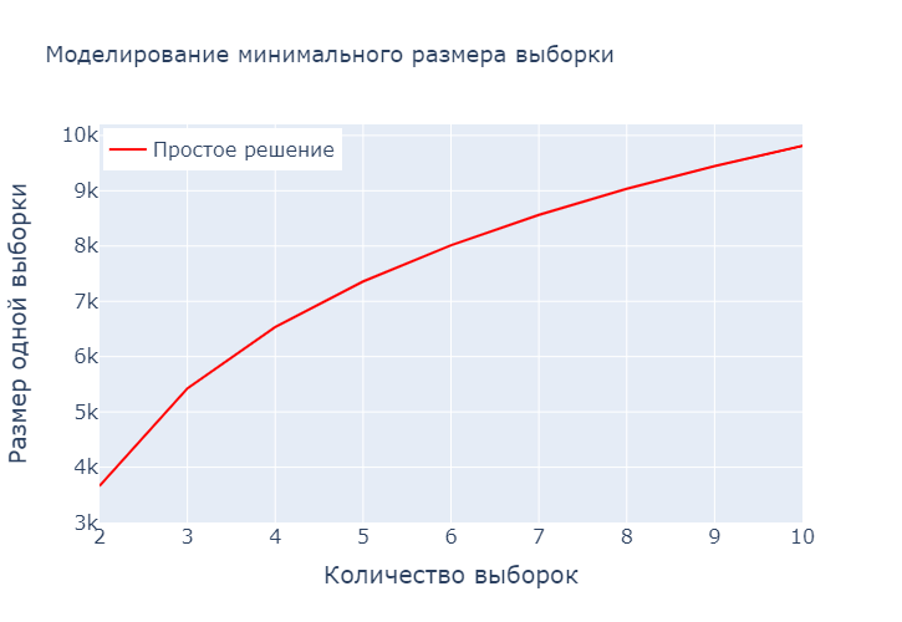
Близкая к нулю частота неверного отклонения нулевой гипотезы влияет на размер одной выборки. Минимальный размер растет при увеличении количества выборок, что сильно скажется на длительности теста.
Решение нас не устраивает, поэтому углубимся в теорию и придумаем другое.
Тест, основанный на предельном сравнении
Мы проверяем гипотезу

против гипотез вида
 что
что  и все средние не равны.
и все средние не равны.
Снова прокомментируем это на примере с баннерами. Гипотеза  означает, что
означает, что  -й баннер дает наибольшую конверсию продажи и она больше конверсии на других баннерах,
-й баннер дает наибольшую конверсию продажи и она больше конверсии на других баннерах,  — все баннеры дают одинаковую конверсию продажи. Но возможен случай, что есть два баннера, которые дают одинаковую конверсию продажи и их конверсия максимальна. Принятие нулевой гипотезы
— все баннеры дают одинаковую конверсию продажи. Но возможен случай, что есть два баннера, которые дают одинаковую конверсию продажи и их конверсия максимальна. Принятие нулевой гипотезы  означает не ее верность, неверность остальных гипотез.
означает не ее верность, неверность остальных гипотез.
Размер одной выборки и построение критерия. Пусть выборки имеют одинаковый размер, заданы уровень значимости  вероятность ошибки второго рода
вероятность ошибки второго рода  и минимальное отклонение
и минимальное отклонение  . Тогда в общем случае для получения минимального размера выборки можно использовать метод Монте-Карло для моделирования квантилей распределений случайных величин
. Тогда в общем случае для получения минимального размера выборки можно использовать метод Монте-Карло для моделирования квантилей распределений случайных величин

где  — независимые случайные величины со стандартным нормальным распределением.
— независимые случайные величины со стандартным нормальным распределением.
Для снижения вычислительной сложности алгоритма выделим частный случай равных дисперсий при нулевой гипотезе  на всех выборках, который наиболее часто встречается на практике (к примеру, тест конверсии). При
на всех выборках, который наиболее часто встречается на практике (к примеру, тест конверсии). При 
где  —
—  -квантиль распределения случайной величины
-квантиль распределения случайной величины
 Доказательство
Доказательство
Пусть критерий  где
где  будет сопоставляться набору выборок
будет сопоставляться набору выборок  номер гипотезы следующим образом. Если
номер гипотезы следующим образом. Если  верна гипотеза
верна гипотеза  . Если
. Если  ни одна из гипотез
ни одна из гипотез  не верна.
не верна.
Составим односторонние гипотезы  . Будем предполагать, что для проверки односторонних гипотез используется такая статистика
. Будем предполагать, что для проверки односторонних гипотез используется такая статистика  что в случае
что в случае она принимает большие по модулю отрицательные значения.
она принимает большие по модулю отрицательные значения.
Положим
 — число, которое мы выберем по уровню значимости
— число, которое мы выберем по уровню значимости  позднее,
позднее,  —
—  -квантиль предельного распределения статистики
-квантиль предельного распределения статистики  при гипотезе
при гипотезе  . Если мы проверяем
. Если мы проверяем  против
против  вероятность ошибки первого рода такого критерия будет равна
вероятность ошибки первого рода такого критерия будет равна  причем в случае ненулевой гипотезы мы можем утверждать стат. значимо об отличии
причем в случае ненулевой гипотезы мы можем утверждать стат. значимо об отличии  от
от  в одну или другую сторону.
в одну или другую сторону.Логично положить  если
если
 — статистика критерия
— статистика критерия  -теста и размеры выборок совпадают, то
-теста и размеры выборок совпадают, то
Можно доказать, что при нулевой гипотезе и неизвестных дисперсиях существует предельное распределение

где  независимы и имеют стандартное нормальное распределение. Стоит отметить, что величины под минимумом зависимы — везде присутствует
независимы и имеют стандартное нормальное распределение. Стоит отметить, что величины под минимумом зависимы — везде присутствует  . Но предельное распределение зависит только от дисперсий.
. Но предельное распределение зависит только от дисперсий.
Критическое множество будет иметь вид
 для каждого
для каждого  можно выбрать с помощью Монте-Карло для заданного
можно выбрать с помощью Монте-Карло для заданного  так, чтобы
так, чтобы при различных
при различных  вероятность ошибки первого рода будет одна и та же.
вероятность ошибки первого рода будет одна и та же.Чтобы посчитать размер выборки  нужно зафиксировать отклонение
нужно зафиксировать отклонение  и вероятность ошибки второго рода
и вероятность ошибки второго рода  . Рассмотрим
. Рассмотрим . Тогда
. Тогда

Дальше можно моделировать для разных  желаемое
желаемое  и по виду кривой понять, какой
и по виду кривой понять, какой  стоит выбрать для каждого
стоит выбрать для каждого  . Положим:
. Положим:

Отдельно рассмотрим случай равных дисперсий при нулевой гипотезе, поскольку нередко при проведении тестов при  предполагаются равные дисперсии
предполагаются равные дисперсии  . Получаем, что предельное распределение имеет вид
. Получаем, что предельное распределение имеет вид

где сходимость подразумевается по распределению. При нулевой гипотезе  в пределе
в пределе  имеют некоторое одинаковое распределение
имеют некоторое одинаковое распределение  и нужно определить только одну константу
и нужно определить только одну константу  для критического множества
для критического множества  -квантилем распределения
-квантилем распределения  . Обозначим
. Обозначим  .
.
Определять размер выборки будем аналогично. В силу того, что мы знаем распределение  при гипотезе
при гипотезе  верно равенство
верно равенство

где  —
—  -квантиль распределения
-квантиль распределения  . Таким образом, мы получаем явное выражение для
. Таким образом, мы получаем явное выражение для 

Что и требовалось доказать.
Мы пришли к тому, что при множественном тестировании выборок можно рассматривать пределы используемых в критерии статистик при достаточно большом размере одной выборки. Это возможно, поскольку для теста требуется много независимых экспериментов. Так, если некоторая  -я выборка стат. значимо лучше каждой другой выборки, принимается гипотеза
-я выборка стат. значимо лучше каждой другой выборки, принимается гипотеза  где
где  иначе принимается гипотеза
иначе принимается гипотеза  . Математически критерий теста описан в доказательстве.
. Математически критерий теста описан в доказательстве.
Моделирование. Мы провели математический разбор критерия, основанного на предельном распределении, который будем называть оптимальным решением. И снова возникает вопрос: решает ли этот метод проблемы, возникшие при попарном сравнении выборок?
Промоделируем частоту неверного отклонения нулевой гипотезы для предыдущего примера для распределения Бернулли.
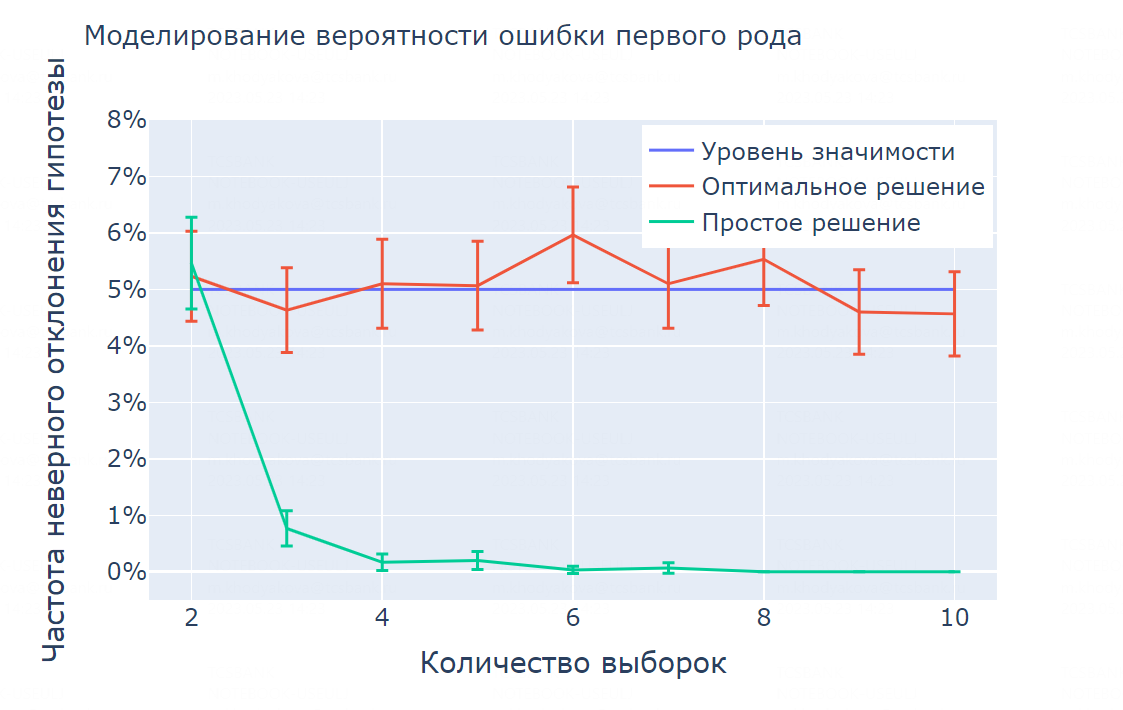
При увеличении количества выборок частота неверного отклонения нулевой гипотезы уже не убывает к нулю, а близка к уровню значимости 5%, который мы заложили.
Мы добились того, чего хотели. Посмотрим, как это влияет на минимальный размер одной выборки.
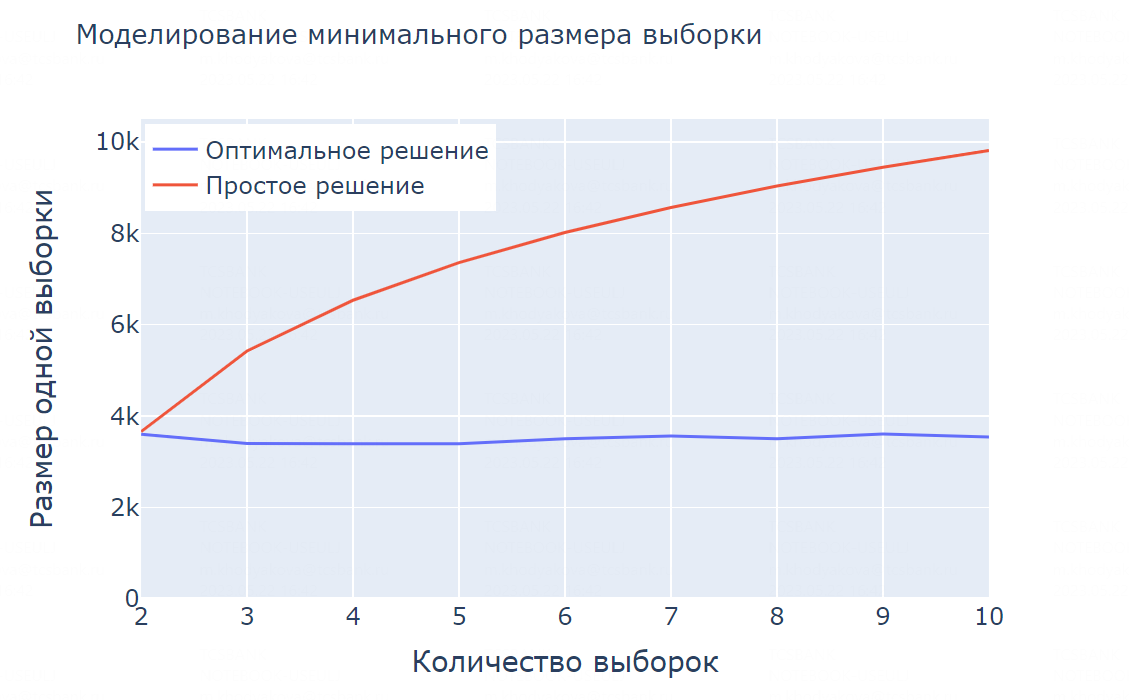
Размер выборки уже не растет при увеличении количества выборок, а остается примерно на одном уровне. Это положительно скажется на длительности теста.
Например, мы решили провести тест десяти выборок, выбрав конверсию целевой метрикой. Тогда при использовании оптимального решения тест займет в три раза меньше времени, чем при использовании простого решения.
Как пользоваться методом, основанным на предельном распределении
Чтобы каждый раз не писать код, мы с коллегами из Сбера оформили инструмент для использования метода, основанного на предельном распределении. Мы создали функции критерия, минимального размера выборки и квантиля предельного распределения в библиотеке HypEx для Python.
Пример кода:
import hypex.abn_test as criteria
alpha = 0.05 # Уровень значимости
beta = 0.2 # Вероятность ошибки II рода
sample_count = 10 # Количество выборок
d = 0.02 # MDE
# Считаем минимальный размер выборки
n = criteria.min_sample_size(number_of_samples=sample_cont,
minimum_detectable_effect=d,
variances=hist_var, # Оценка дисперсии по историческим данным
significance_level=alpha,
power_level=beta,
equal_variance=True)
# Номер принятой гипотезы
res = test_on_marginal_distribution(sample_list, # Массив выборок
significance_level=alpha)Перейдя по ссылкам, можно посмотреть
Заключение
Мы построили метод множественного тестирования, который позволяет нам ошибаться ровно с той вероятностью, которую мы закладываем. А еще создали инструмент для реализации теста. Построенный метод дает нам возможность не увеличивать размер одной выборки и проводить множественное тестирование быстрее в несколько раз.
Надеюсь, эта статья будет вам полезна на практике. Если есть вопросы, оставляйте их в комментариях.
