Опыт создания хранилища Ceph c пропускной способностью тебибайт в секунду
Инженер из компании Clyso обобщил опыт создания кластера хранения на базе отказоустойчивой распределённой системы Ceph с пропускной способностью, превышающей тебибайт в секунду. Отмечается, что это первый кластер на базе Ceph, который смог достигнуть подобного показателя, но перед получением представленного результата инженерам потребовалось преодолеть серию не очевидных подводных камней.
Например, для повышения производительности на 10–20% было достаточно включить на серверах в настройках энергосбережения BIOS работу только в режиме максимальной производительности и отключить c-state (c-state меняет параметры энергосбережения в зависимости от нагрузки, что отражается на Ceph). Также оказалось, что при использовании накопителей NVMe ядро Linux значительное время тратит на обработку spin-блокировок в процессе обновления маппинга IOMMU. Отключение IOMMU в ядре привело к заметному росту производительности в тестах записи и чтения блоков, размером 4MB.
При этом отключение IOMMU не решило проблему с проседанием производительности при случайной записи блоков, размером 4KB. Разбираясь в чём дело, инженеры натолкнулись на исправления в сборочных сценариях Ceph от проектов Gentoo и Ubuntu, которые включали сборку с опцией RelWithDebInfo, так как с ней в GCC применялся режим оптимизации »-O2», при котором заметно возрастала производительность Ceph. К снижению производительности также приводила компиляция с библиотекой TCMalloc. Изменение флагов компиляции и прекращение использования TCMalloc привело к снижению времени упаковки (compaction) в три раза и повышению производительности случайных операций записи блоками 4K в два раза. В финале дополнительно была произведена оптимизация настроек Reef RocksDB и групп размещения (PG).
Кластер сформирован из 68 узлов на базе серверов Dell PowerEdge R6615 с CPU AMD EPYC 9454P 48C/96T. Каждый узел содержит 10 NVMe-накопителей Dell 15.36TB, два Ethernet-адаптера 100GbE Mellanox ConnectX-6 и 192 ГБ ОЗУ. Программное обеспечение основано на Ubuntu 20.04.6 и Ceph 17.2.7. В кластере на 63 узлах поднято 630 OSD (Оbject Storage Daemon, фоновый процесс управляющий хранением данных в локальном хранилище, по одному OSD на NVMe-накопитель), три процесса MON (monitor, отслеживает состояние кластера) и один процесс MGR (Manager, управляющий сервис). Размер хранилища 8.2 ПБ.
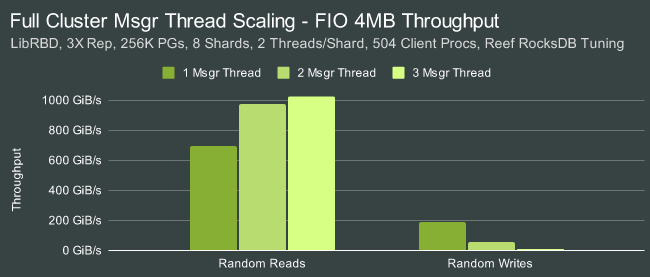
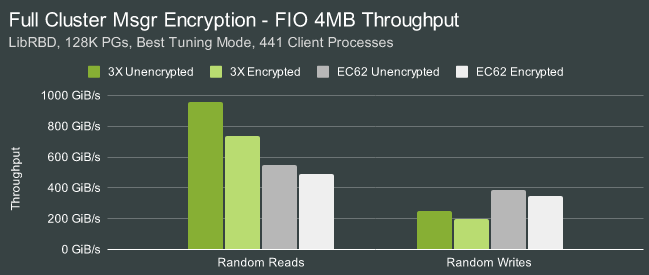
Пропускная способность при последовательных операциях чтения блоков 4М составила 1025 GiB/s, записи — 270 GiB/s. При случайном чтении блоков 4KB производительность составила 25.5 миллионов операций чтения в секунду и 4.9 млн при записи. Включение шифрования уменьшило пропускную способность при чтении примерно до 750 GiB/s. При задействовании кодов коррекции ошибок EC62 пропускная способность составила 547 GiB/s при чтении и 387 GiB/s при записи (скорость записи оказалась выше чем без кодов коррекции), а при случайном доступе 3.4M IOPS при чтении и 936K IOPS при записи.
Дополнительно можно отметить, что в сентябре похожий рубеж пропускной способности в тебибайт в секунду был достигнут в эксабайтном кластере хранения CERN, реализованном на базе открытого распределённого хранилища EOS, построенного на базе протокола XRootD.
Источник: http://www.opennet.ru/opennews/art.shtml? num=60470
Полный текст статьи читайте на OpenNet
